前面介绍了一下关于如何衡量处理器性能,还有一些关于功耗的问题,感觉不太重要就随便听了一下,所以也没记笔记。
Pipelining

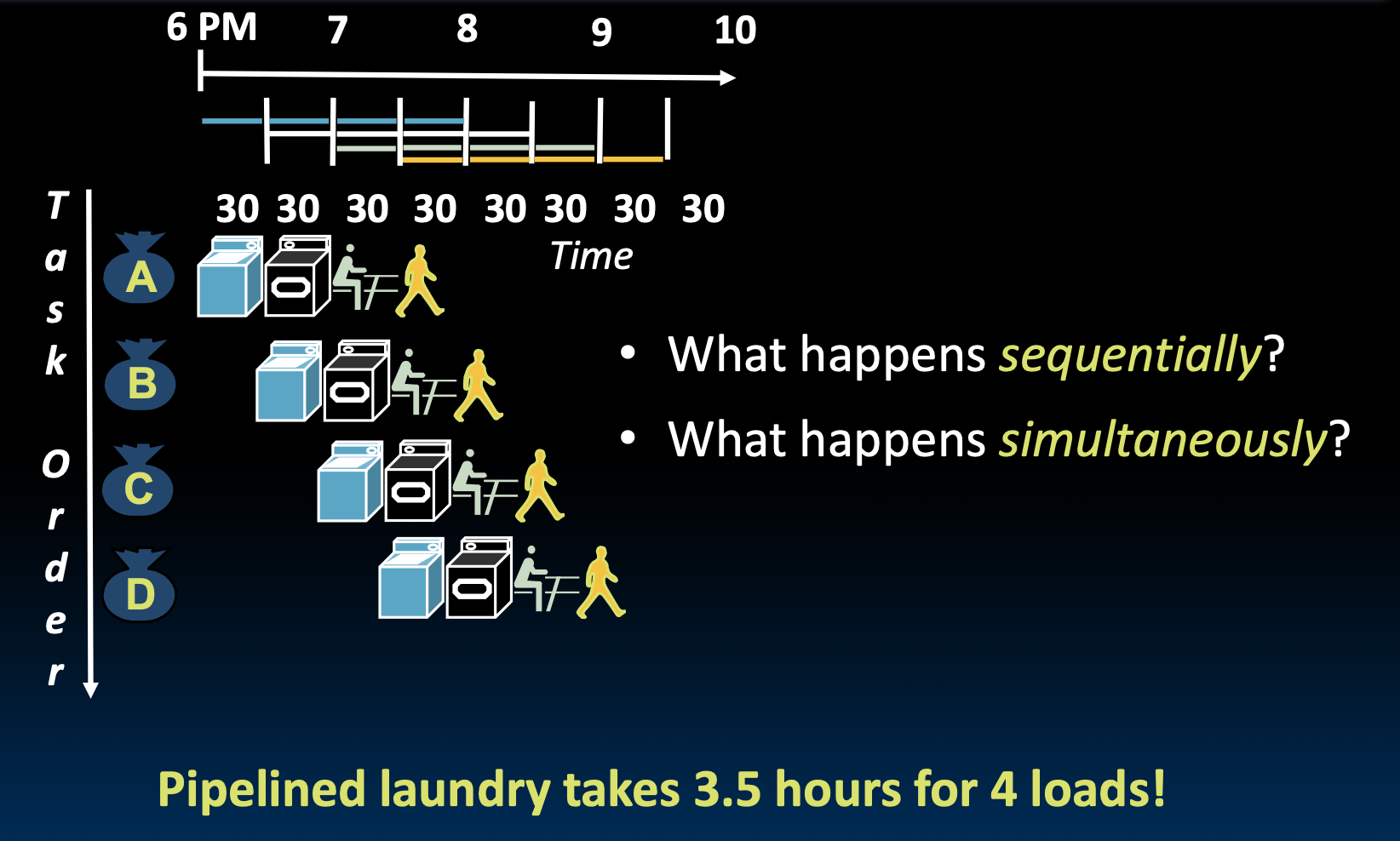
用流水线来提高吞吐量
-
流水线的作用:
-
流水线不会减少单个任务的延迟,但它可以提高整个工作负载的吞吐量。
-
流水线允许多个任务同时使用不同的资源。
-
-
加速的潜力:
- 流水线的理论加速等于流水线的阶段数。
-
填充和排空时间:
- 填充和排空流水线的时间会减少加速。
如果我们把洗衣服和装衣服的时间缩短到20min,流水线会变得更快吗?
答案是不会,速度受最慢的阶段限制。
pipelining RISCV
Sequential vs Pipelining
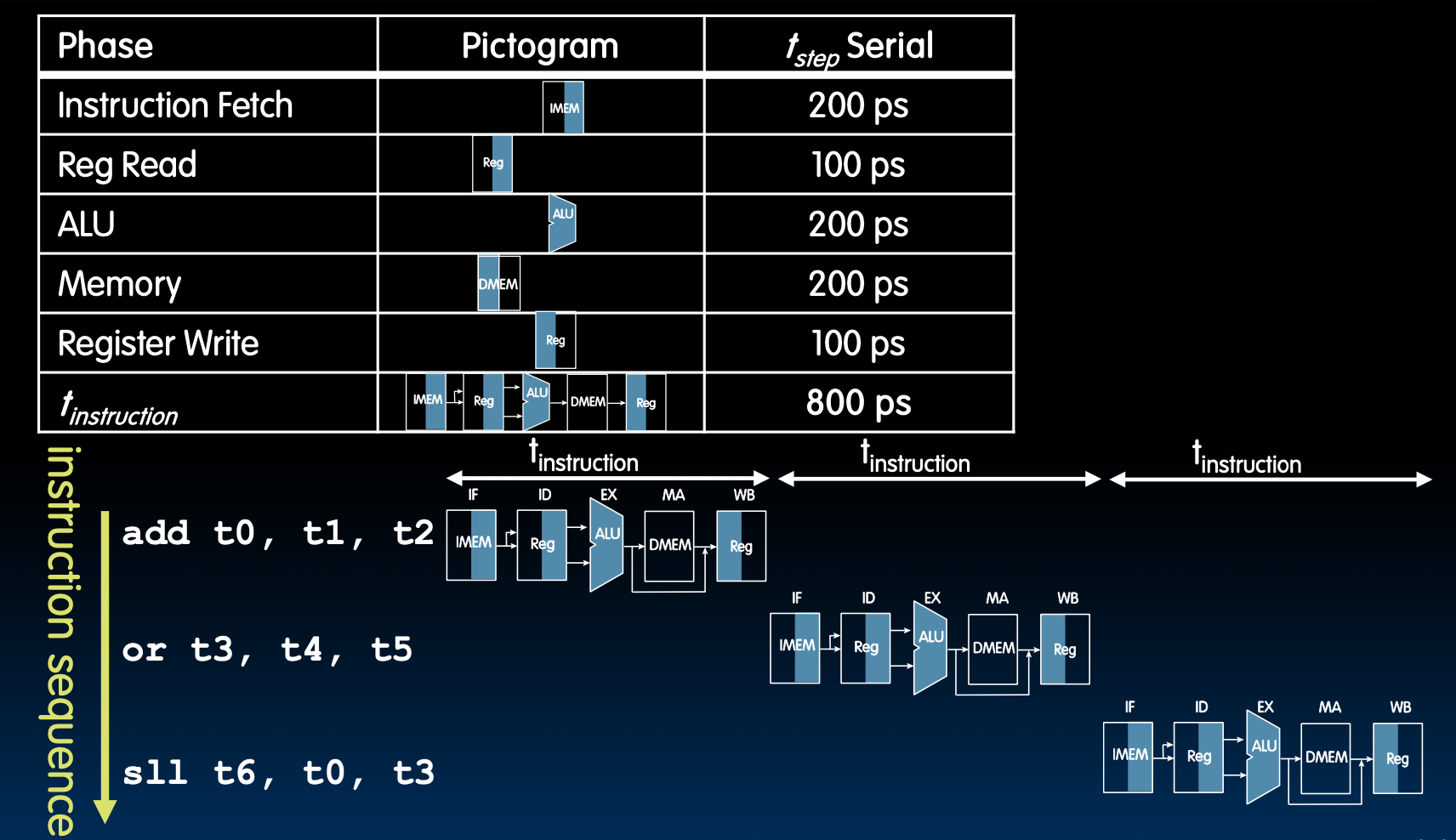
注意,这里的Reg Read/Write只需要100ps,这点我们在后面会提到
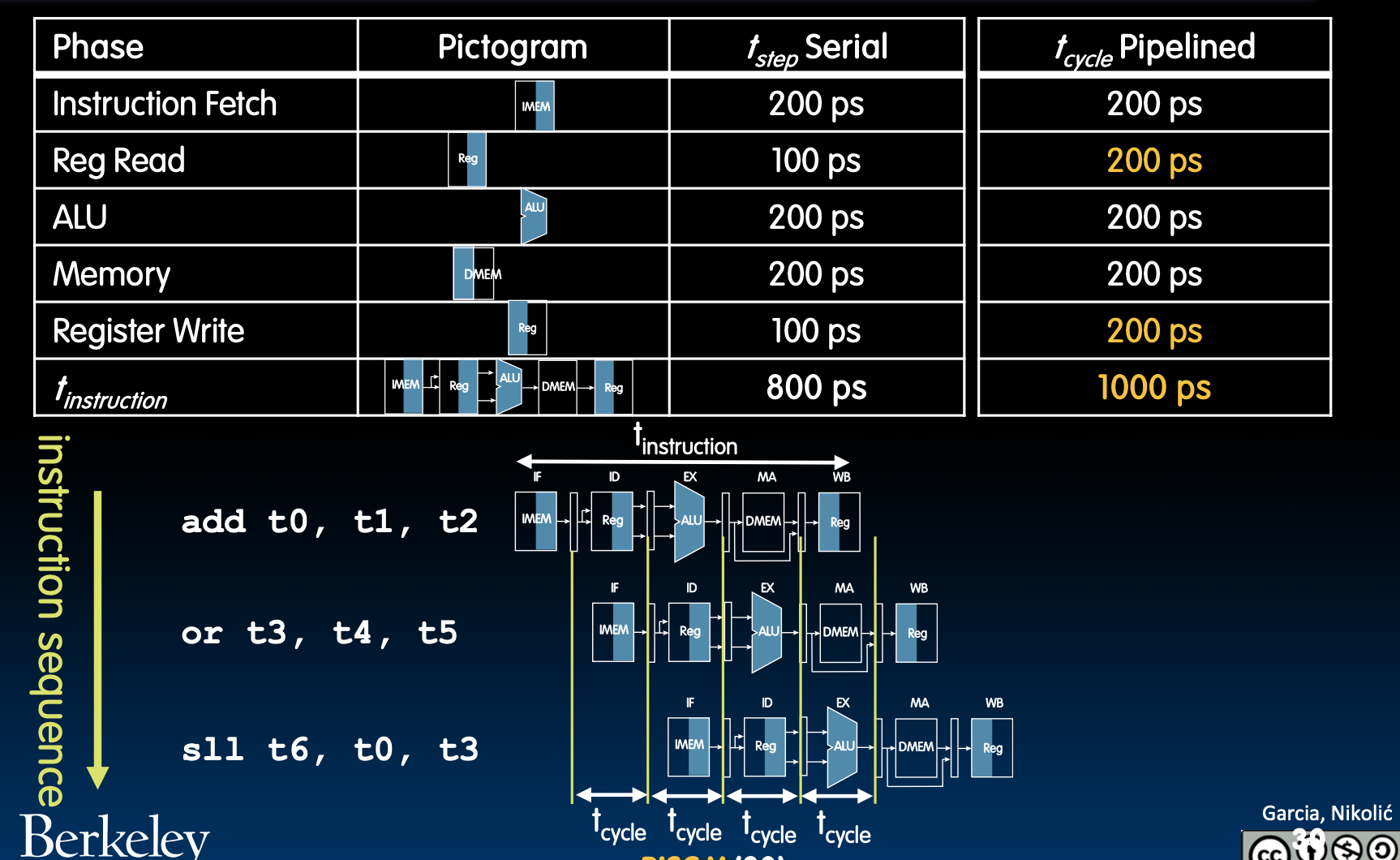
注意,Register Read/Write因为要和流水线中延迟最大的一部分一样,所以时间也变成了200ps。如果短于这个时间,有些操作还没结束就到下一个时钟周期了。

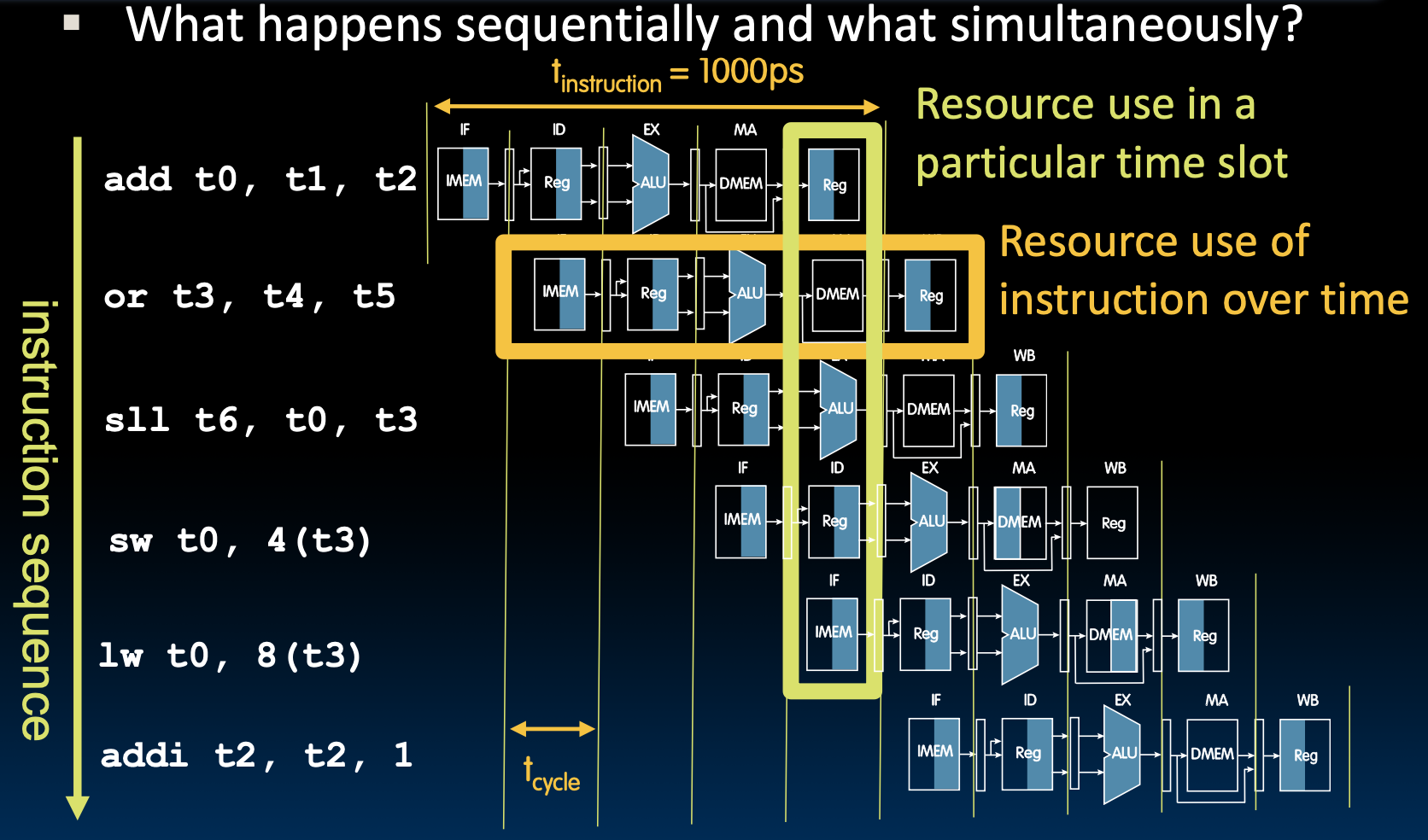
观察or指令,实际上他的DMEM并没有被用上,他只是在等add用完Reg而已。
Pipelining Datapath
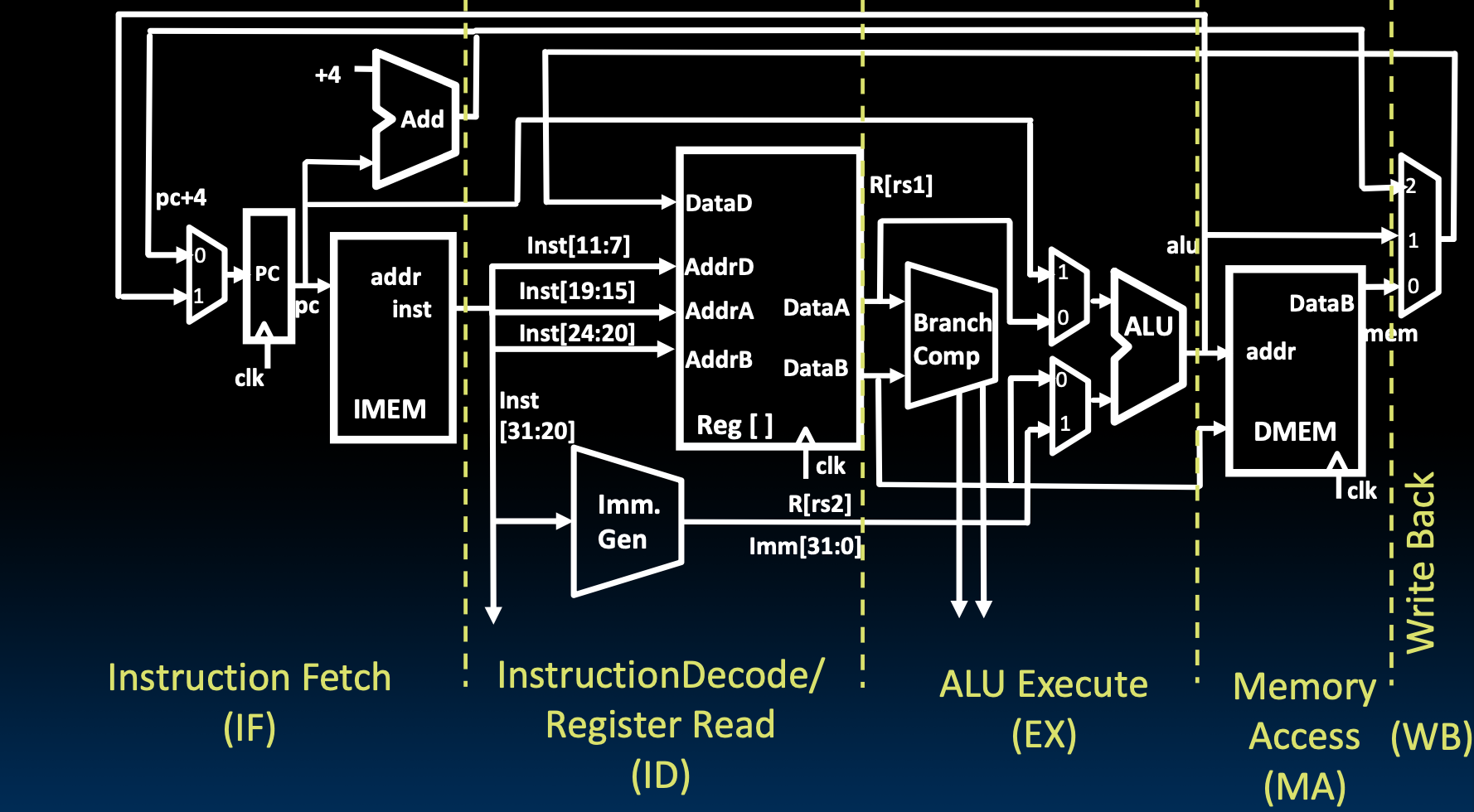
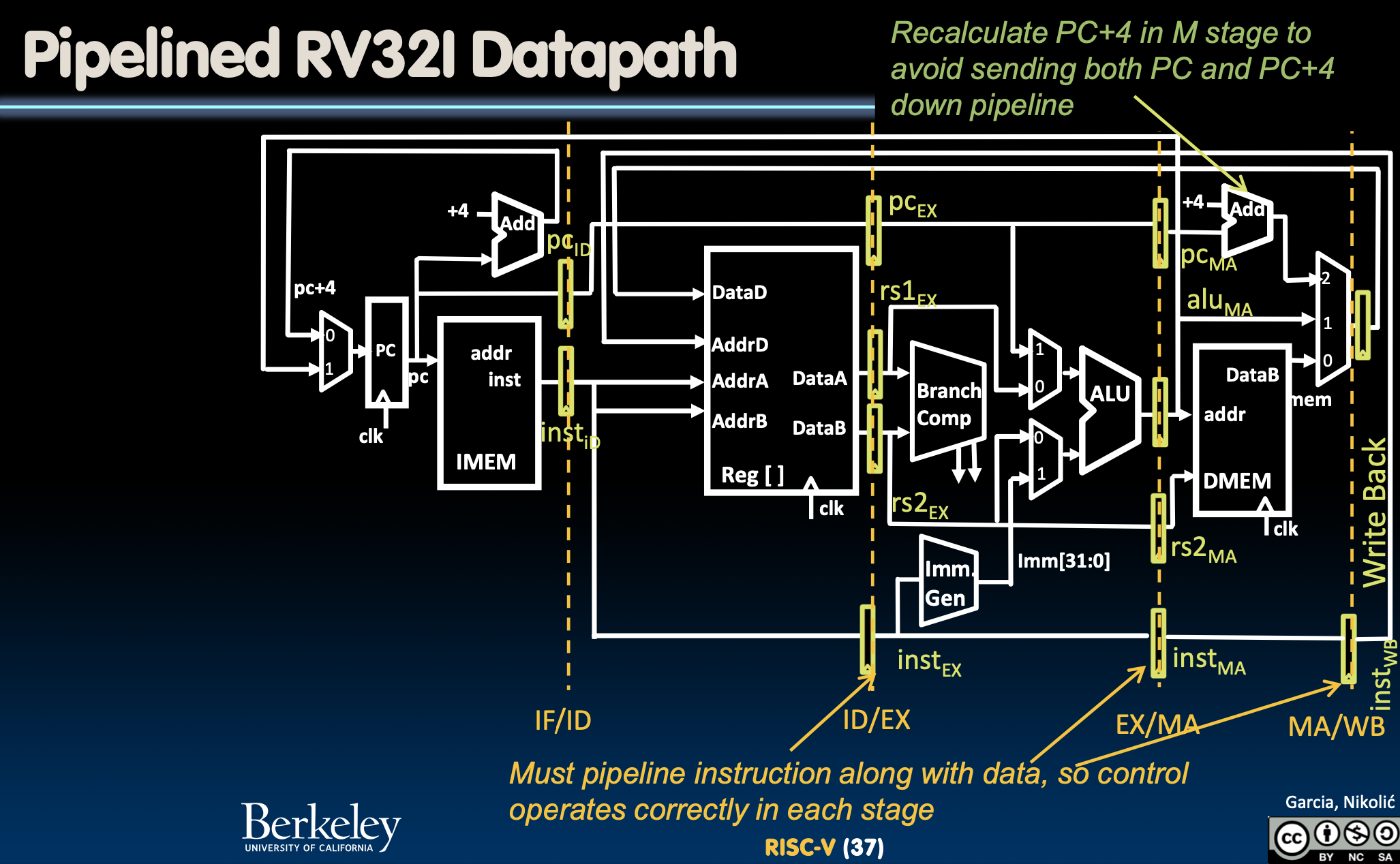
注意右上角的加4的加法器,那是用于优化设计采用的方案。
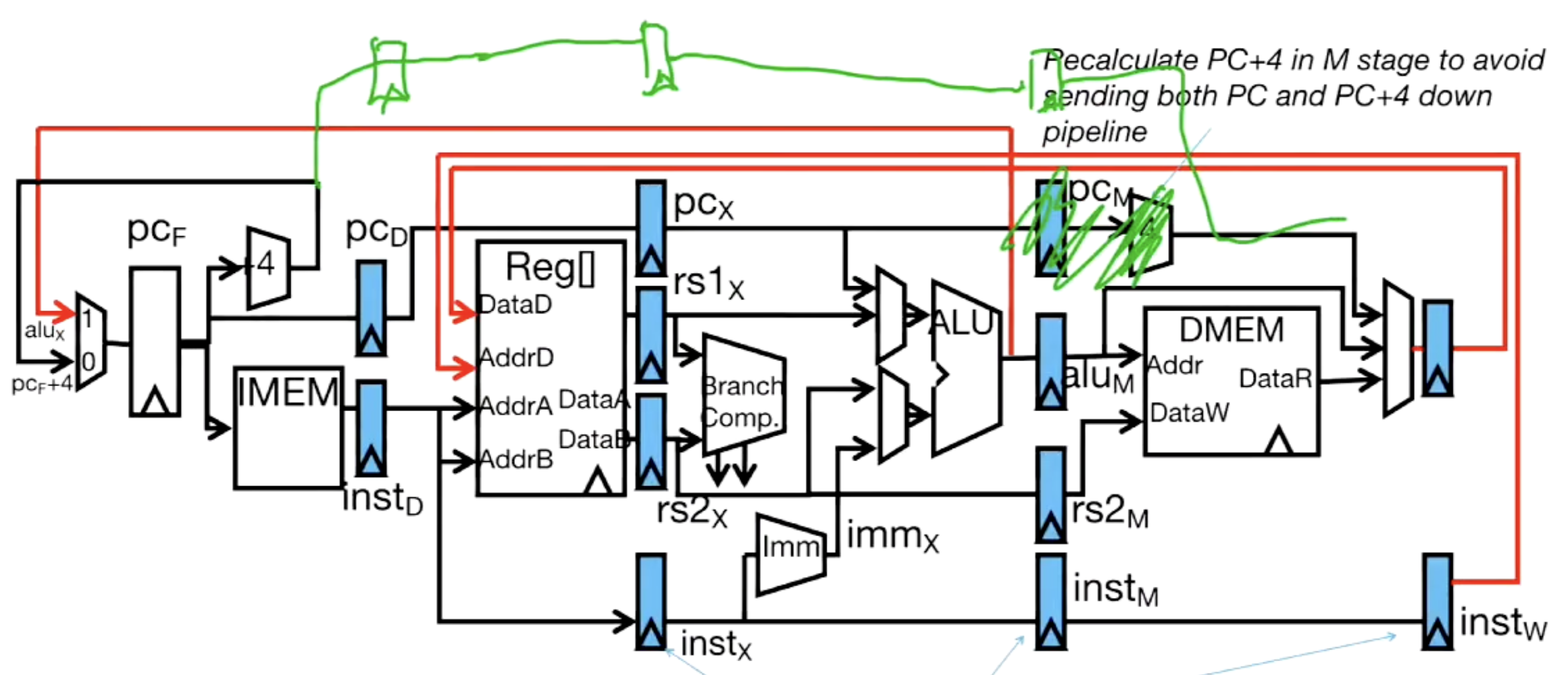
如果我们不加这个加法器,那么我们就需要用三个寄存器来保存PC+4。就像下面这样
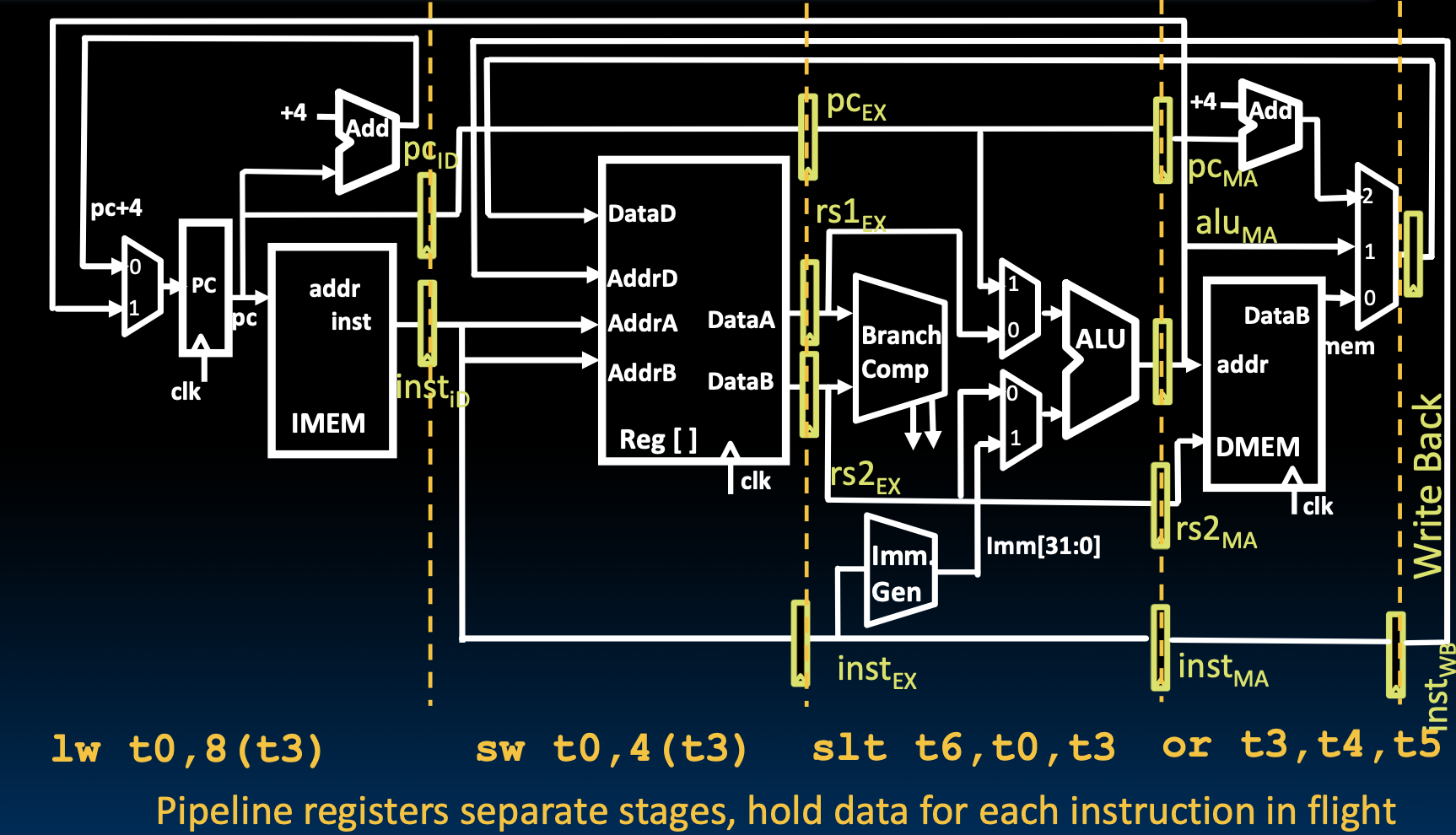
下面是命令和流水线数据通路的示意图
Pipelined Control
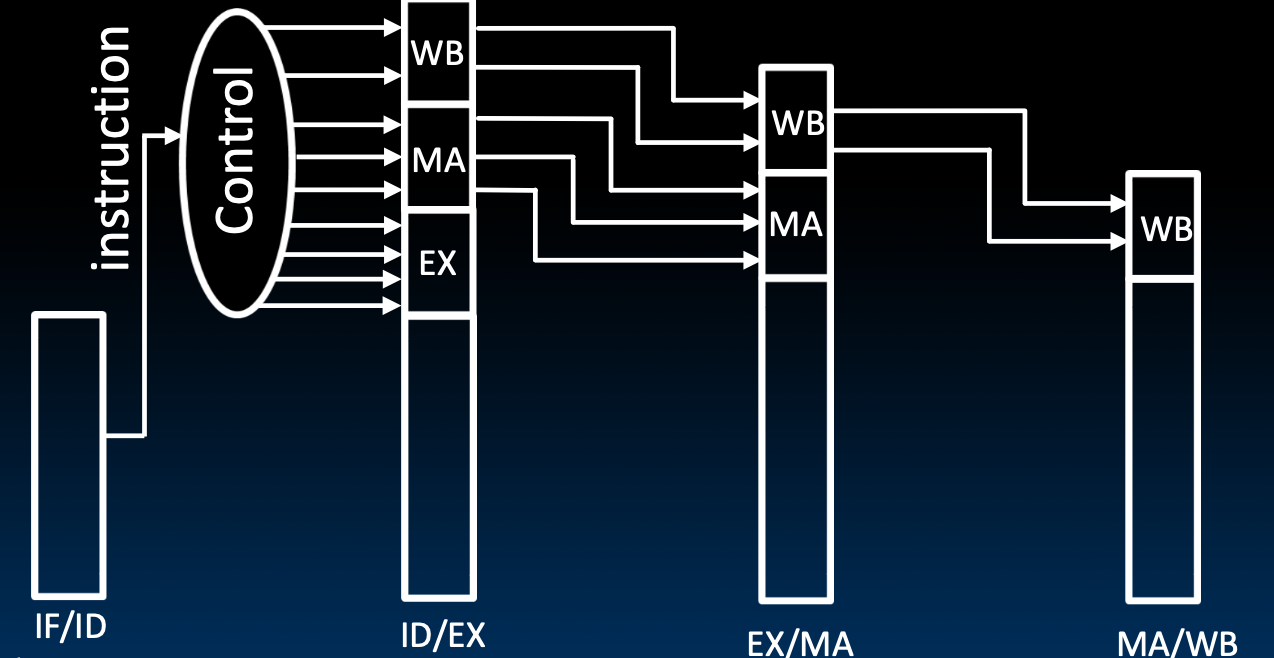
除了指令,我们要需要往流水线下游发送控制位,我们还需要保存控制位!
还有一种办法,在su20讲了,但是我没听明白是咋回事,所以接着往下看吧。
Pipeline Hazards
流水线中有一种情况,在下一个时钟周期中下一条指令无法执行。这种情况被称为冒险(hazard),这一部分在教材软硬件接口里面讲的很详细。
有三种类型的冒险:
-
结构冒险
-
数据冒险
-
控制冒险
Structural hazard
结构冒险:因缺乏硬件支持而导致指令不能再预定的时钟周期内执行的情况。
比如在洗衣服的例子中,洗衣机和烘干机被换成洗衣烘干一体机,或者你的舍友在收衣服的时候跑去干别的事情了,这都会发生结构冒险,我们设计的流水线就会被破坏。
解决方案:
-
指示轮流使用资源,有些指示必须暂停。
-
往机器里加更多硬件,可以通过增加更多硬件来解决结构性危险
但是RISCV指令系统是面向流水线设计的,所以设计人员在设计流水线的时候很容易避开结构冒险。
寄存器文件的结构冒险:
-
因为每个指令:
-
在解码阶段可以读取最多两个操作数。
-
在写回阶段可以写入一个值。
-
-
所以通过具有独立的端口来避免结构性冒险:
- 两个独立的读端口和一个独立的写端口。
-
而且寄存器堆的读写的速度很快,比处理器中其他单元更快,只有这样我们才能避免资源短缺,所以就像我们在前面提到的寄存器读写是在100ps内,实际上就是这个原因。
-
因此每个周期可以同时发生三个访问,避免了结构冒险。
Structural Hazard: Memory Access
如果,我们的IMEM和DMEM没有被分开,就会出现结构冒险。
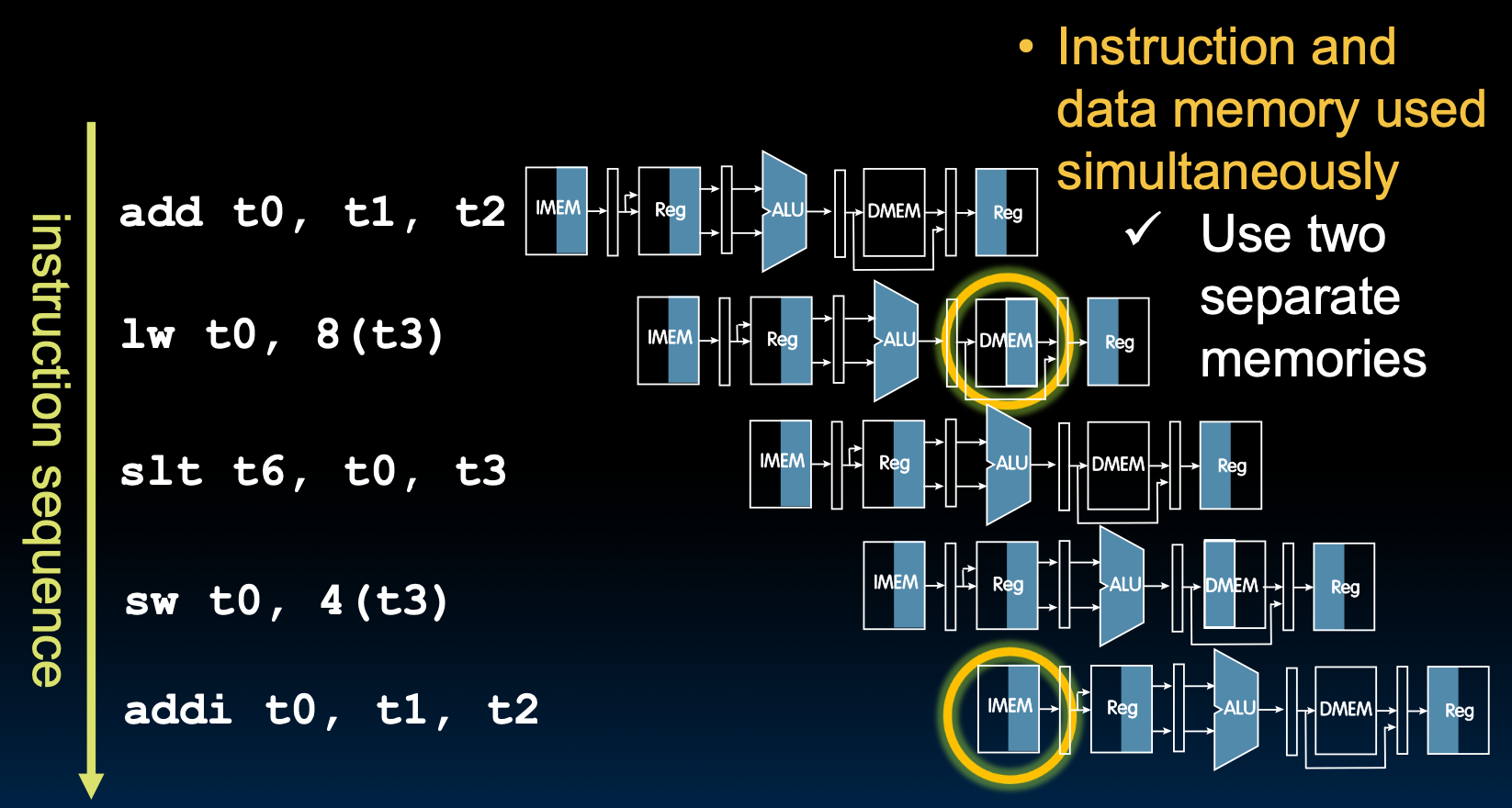
Instruction and Data Caches
CPU上的高速缓存
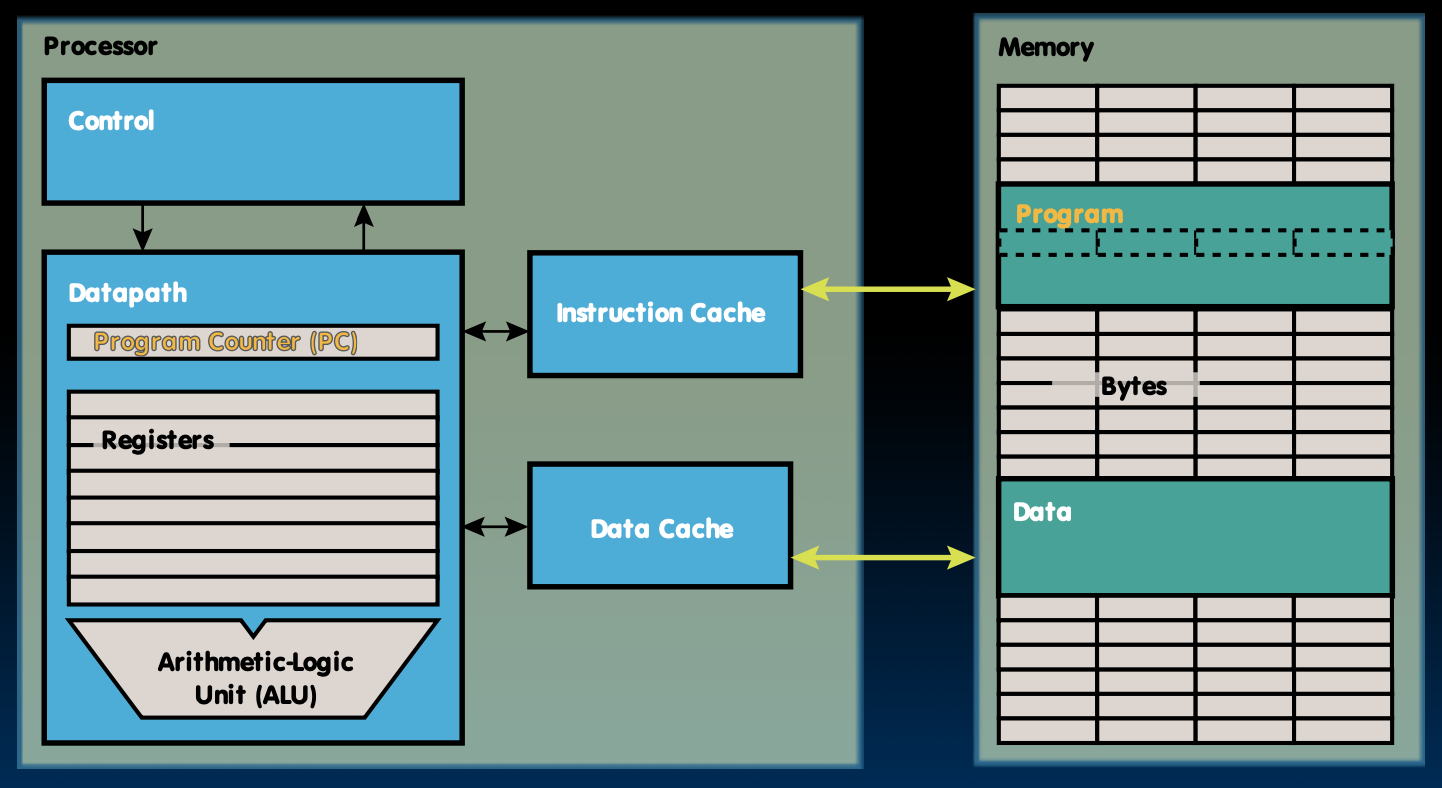
Structural Hazards Summary
结构冒险定义
结构性危害是指由于硬件资源的竞争导致的流水线停顿。这通常发生在多阶段处理器的设计中,其中多个阶段试图在同一时钟周期内访问同一个硬件资源。
在RISC-V流水线中的例子
在RISC-V架构的单内存流水线设计中,载入/存储指令(load/store instructions)需要访问内存。如果没有独立的指令和数据内存,那么在内存被载入或存储操作占用时,指令的获取(fetch)就会受到影响,从而导致整个流水线必须暂停一个周期。
解决方案
为了减少这种类型的冲突,流水线设计通常会采用以下几种方法之一:
-
分离指令和数据内存:通过使用不同的内存来存储指令和数据,这样即使数据内存被访问,指令内存仍然可以用于下一条指令的获取。
-
分离指令和数据缓存:如果物理上分开指令和数据内存不可行或者成本太高,也可以选择使用独立的指令缓存和数据缓存。这样可以在一定程度上缓解资源竞争的问题。
RISC ISA 设计考虑
像RISC-V这样的精简指令集计算机(RISC)体系结构被设计成能够最小化结构性危害。例如,它们限制了每条指令只能有一个内存访问,这样可以减少不同指令之间争夺内存访问权的情况。
Data Hazards(R-Type)
由于一个步骤必须等待另一个步骤完成而导致的流水线停顿叫做数据冒险。
假设你在叠衣服时发现一只袜子找不到与之匹配的另一只。一种可能的策略是跑到房间,在衣橱中找,看是否能找到另一只,很显然,在找袜子的时候,下面的流程不得不停下来等待。
计算机中的例子:
add x19, x0, x1
sub x2, x19, x3
下面的sub里的x19就需要上一条命令计算完成后才能使用,这将浪费三个时钟周期。

如上图所示,在这个阶段,下面的寄存器到底是读出旧值,还是读出刚刚在add这条命令写入的新值呢?
实际上寄存器堆被设计为单周期内可以完成读写操作,也就是说,一个周期内,前半个周期可以写,后半个周期可以读。
在标准的五级流水线中,大概率不会出现问题,但是在一些高频率流水线中,可能会出问题
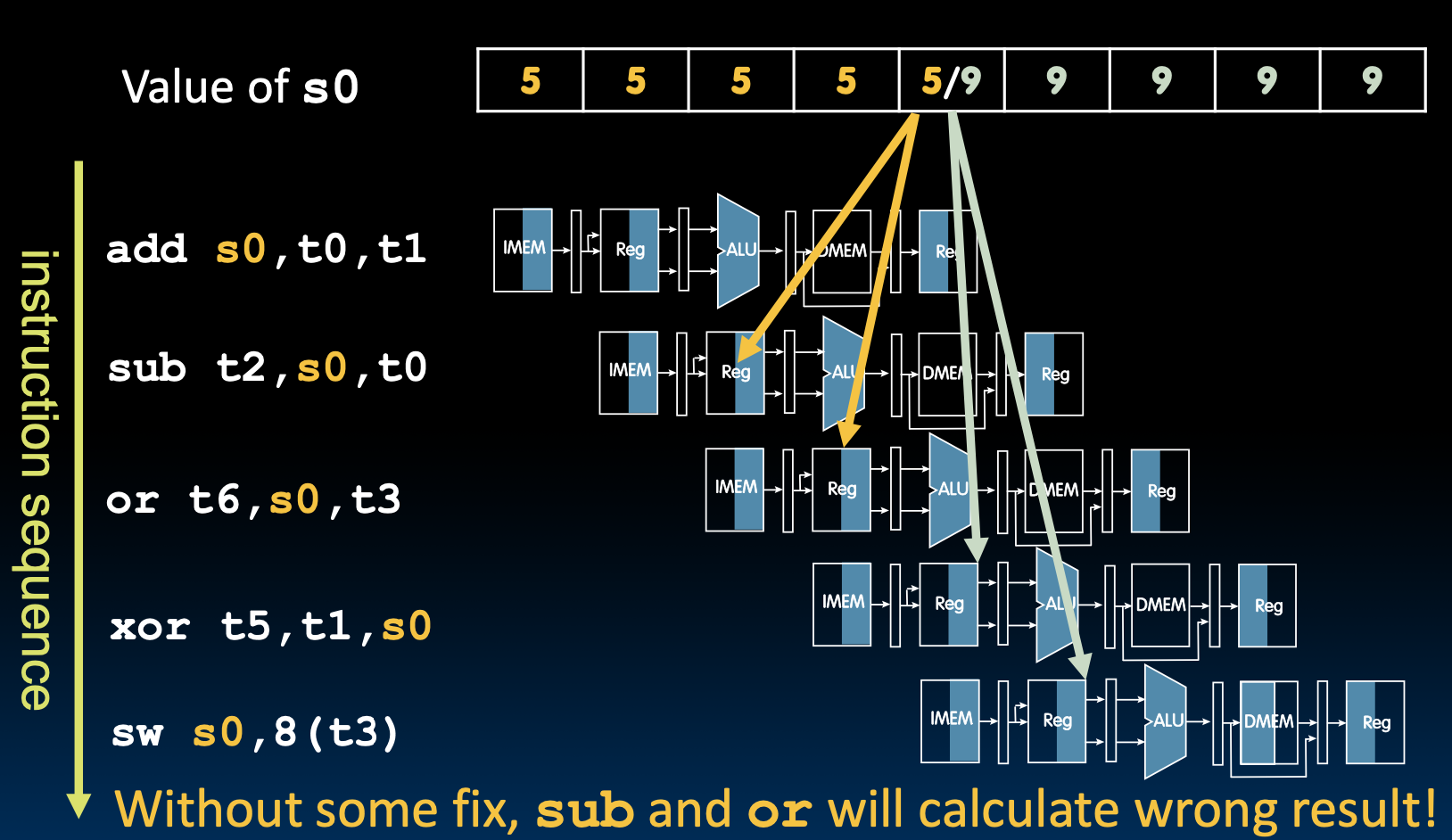
下面的所有指令都依赖于s0,但是s0在add指令快结束的时候才会被写会寄存器,这导致了后面的两条指令得到了错误的s0。
Solution 1: Stalling
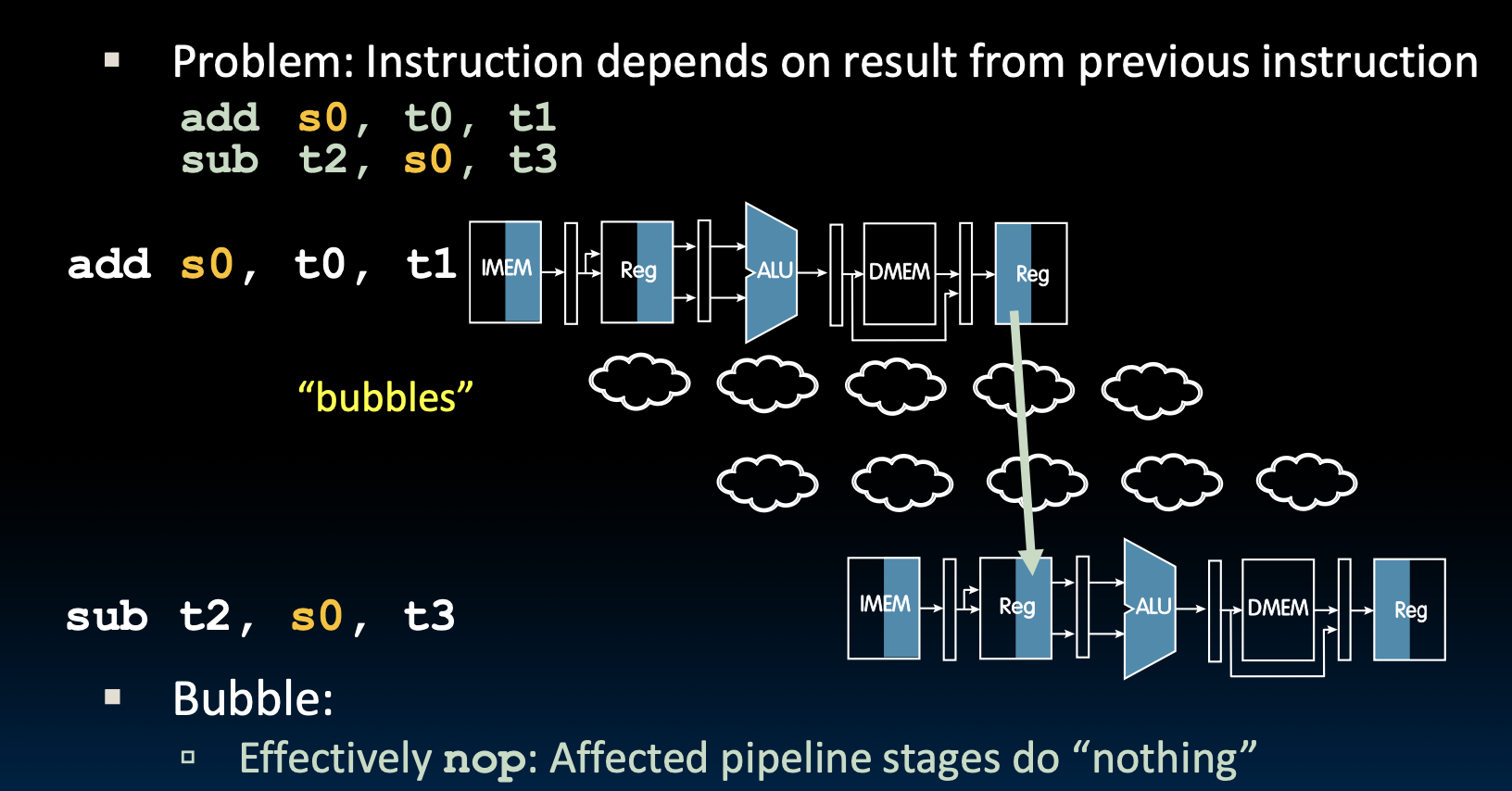
让程序啥事也不干,等待下一条指令的对齐。这个重要概念的正式叫法为流水线停顿(pipeline stall),俗称气泡(bubble)。但这样会降低性能,不过可以获得正确的结果。
编译器通常会找一些不依赖于上一条指令的命令,放在需要bubble的地方,以此来对齐,但是如果找不到,就执行nops(addi x0, x0, 0),等待对齐。
Solution 2: Forwarding
前递(Forwarding),提前从内部缓冲中去到数据,而不是等到数据到达程序员可见的寄存器或存储器。
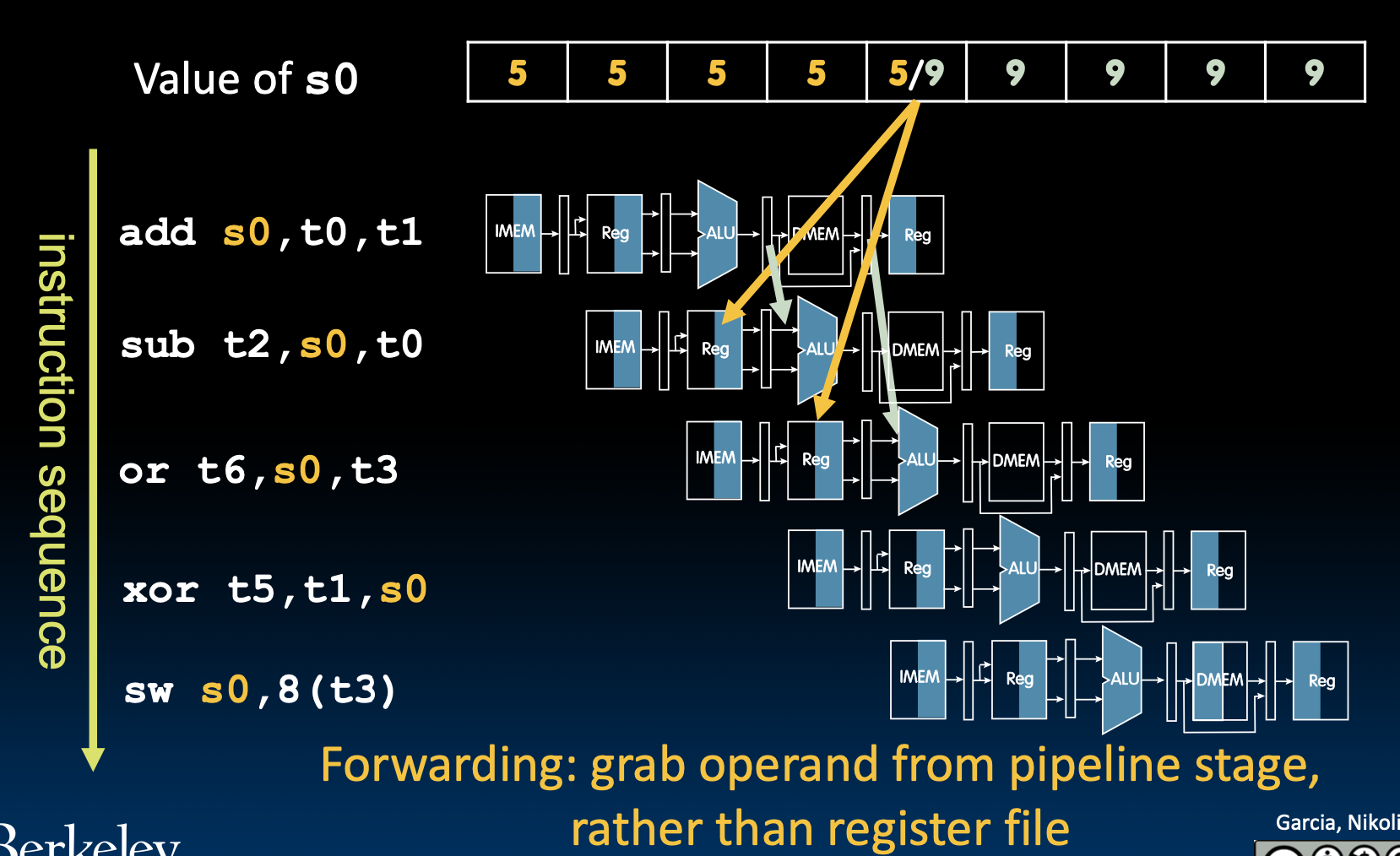
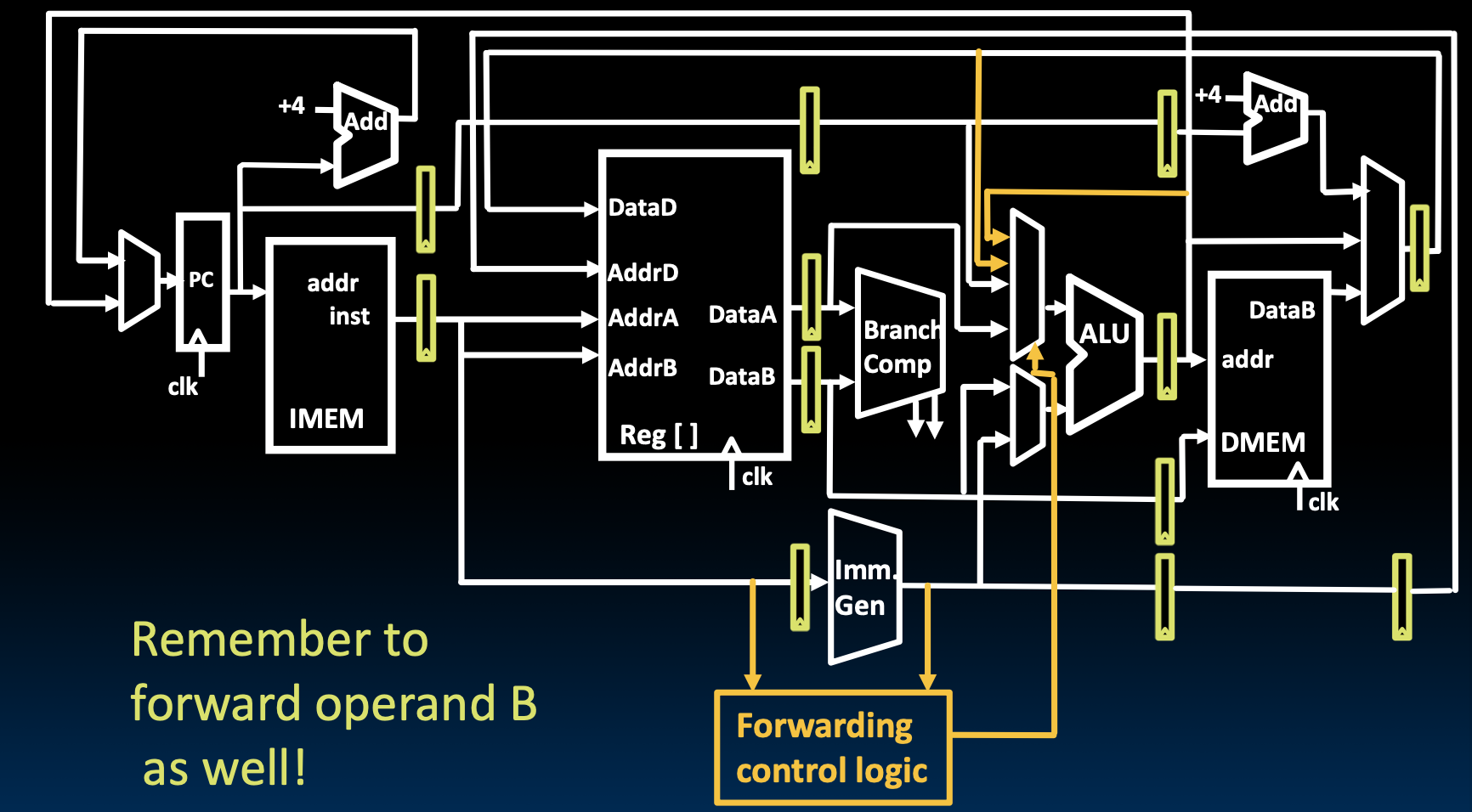
但是这样需要额外的数据通路。
那么既然要增加电路,我们就需要知道什么情况下,才需要进行前递操作。
比较旧的目的寄存器和新指令的源寄存器,如果是一样的话就需要进行前递操作,注意!要忽略x0。
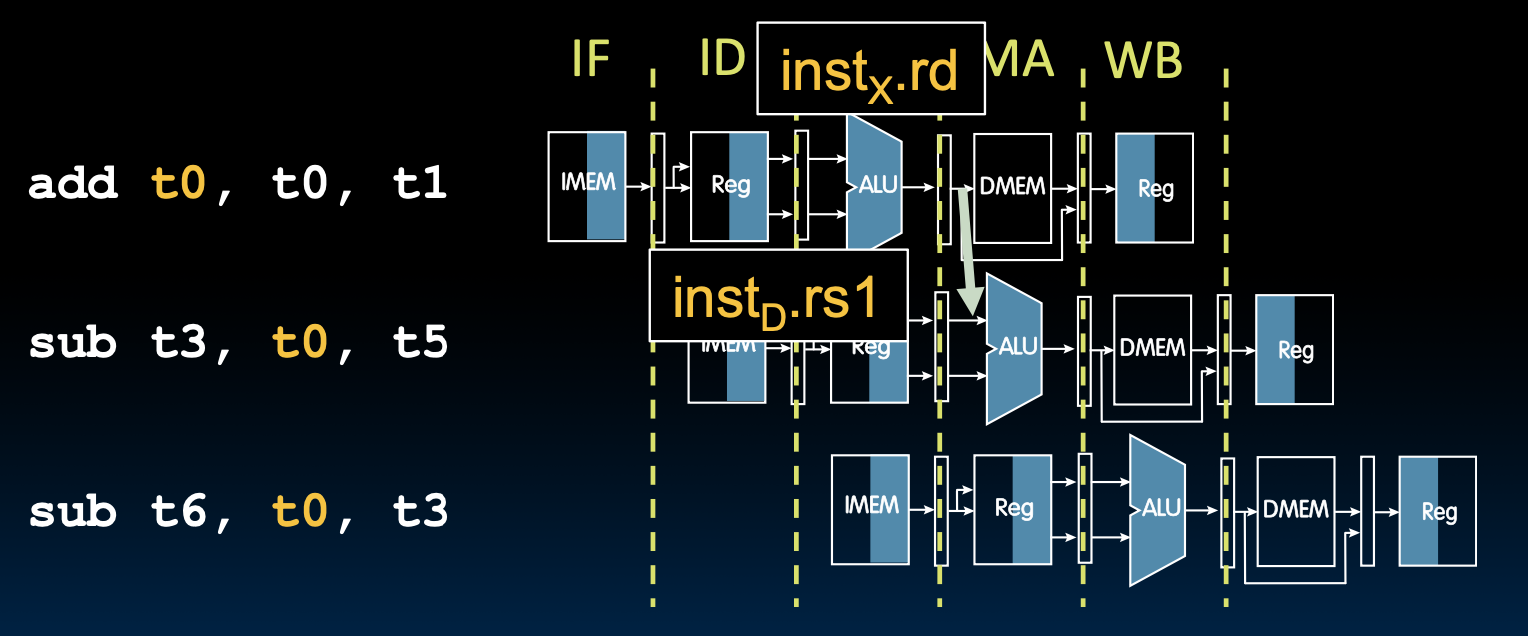
Data Hazards(Load)
在lw操作中,DMEM之后才能获得数,这就意味着我们需要将书传到下一条指令的前一个周期,但是在流水线中,我们不能后退。
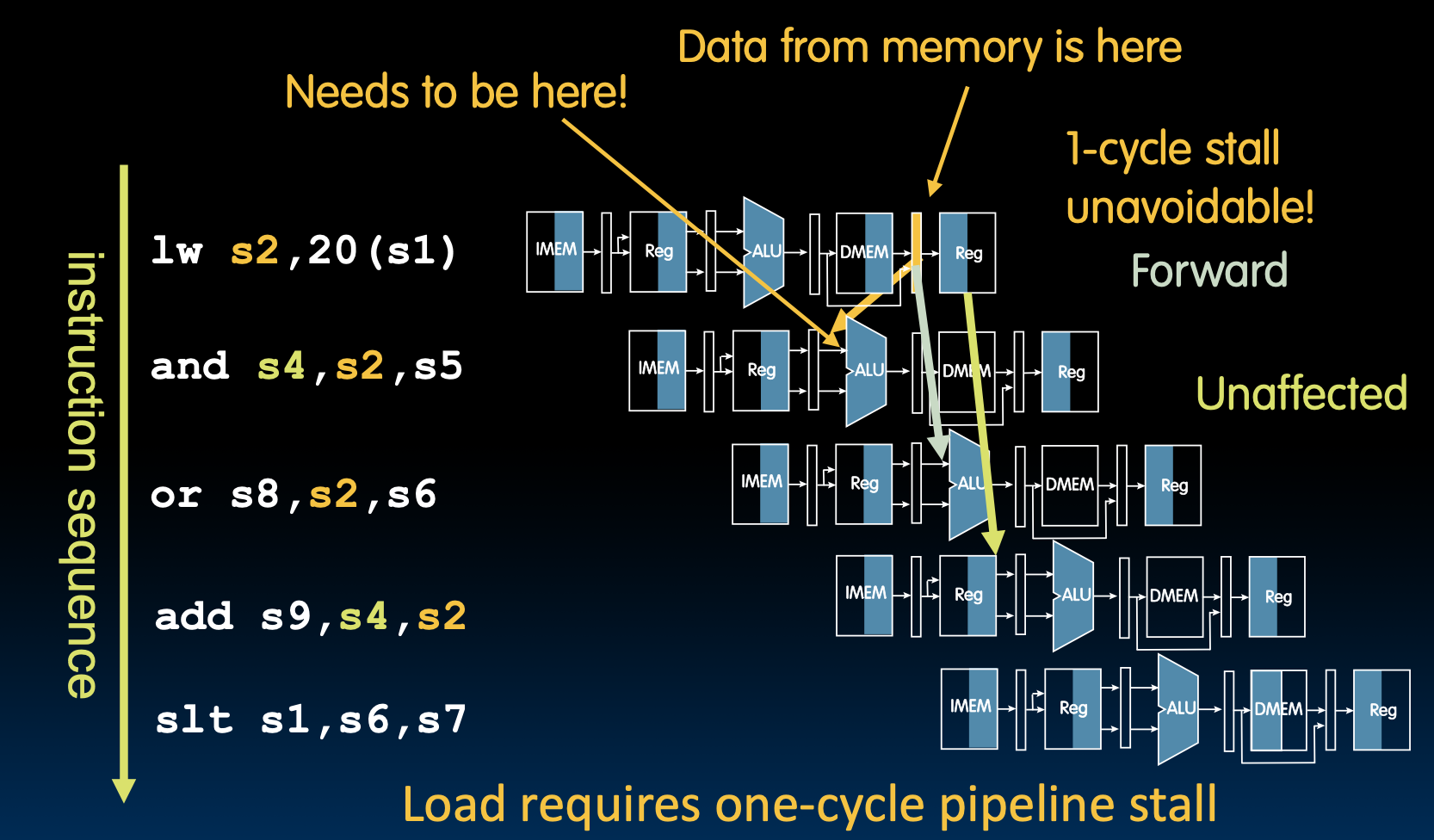
所以,我们只能采用stall和下一条命令对齐,这是一个不可避免的一周期停顿,但是除了下一条以外的命令,我们就可以前递过去了。
Stall Pipeline
所以我们该怎么停顿呢?我们怎么把已经获取到的and指令变成nop呢?
一旦我们发现了需要停顿,我们就会把所有写入新状态的关联控制信号设置为否,这样我们就无法寄存器堆,内存和更新PC。如果没有状态更新,那么我们的下一条指令就依然是相同的指令!
所以我们需要一个机制来检测我们正在处理一个lw,并且加载的目的寄存器是下一条指令的源寄存器。
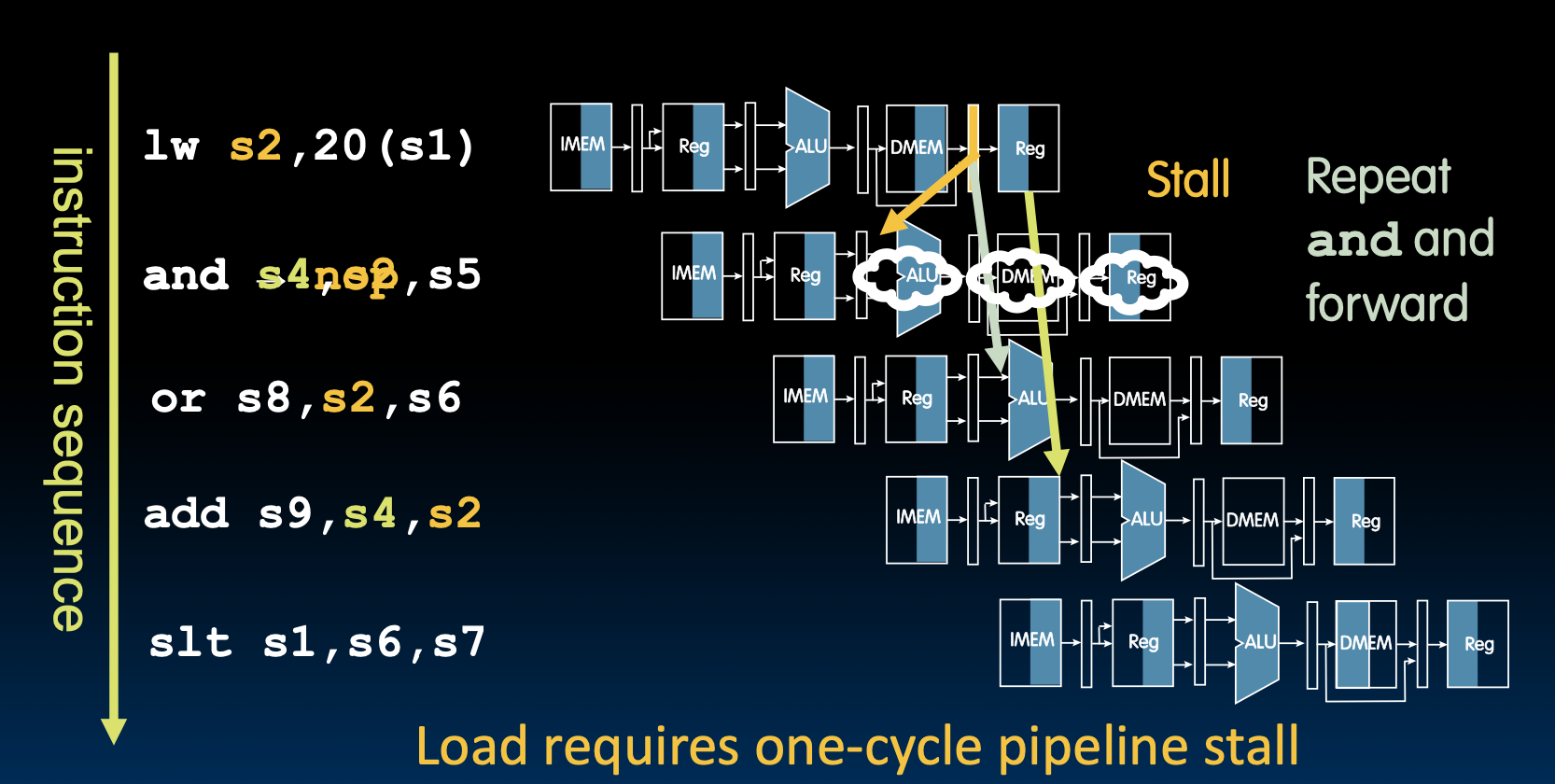
加载后的插槽称为加载延迟插槽
如果该指令使用了加载的结果,那硬件会停顿一个周期,相当于在插槽中插入一个nop指令,只是后者会占用更多的代码空间。性能会有所损失。
为了降低损失:将不相关的指令放入加载延迟插槽中,这样就不会有性能损失!
Code Scheduling to Avoid Stalls

Control Hazards
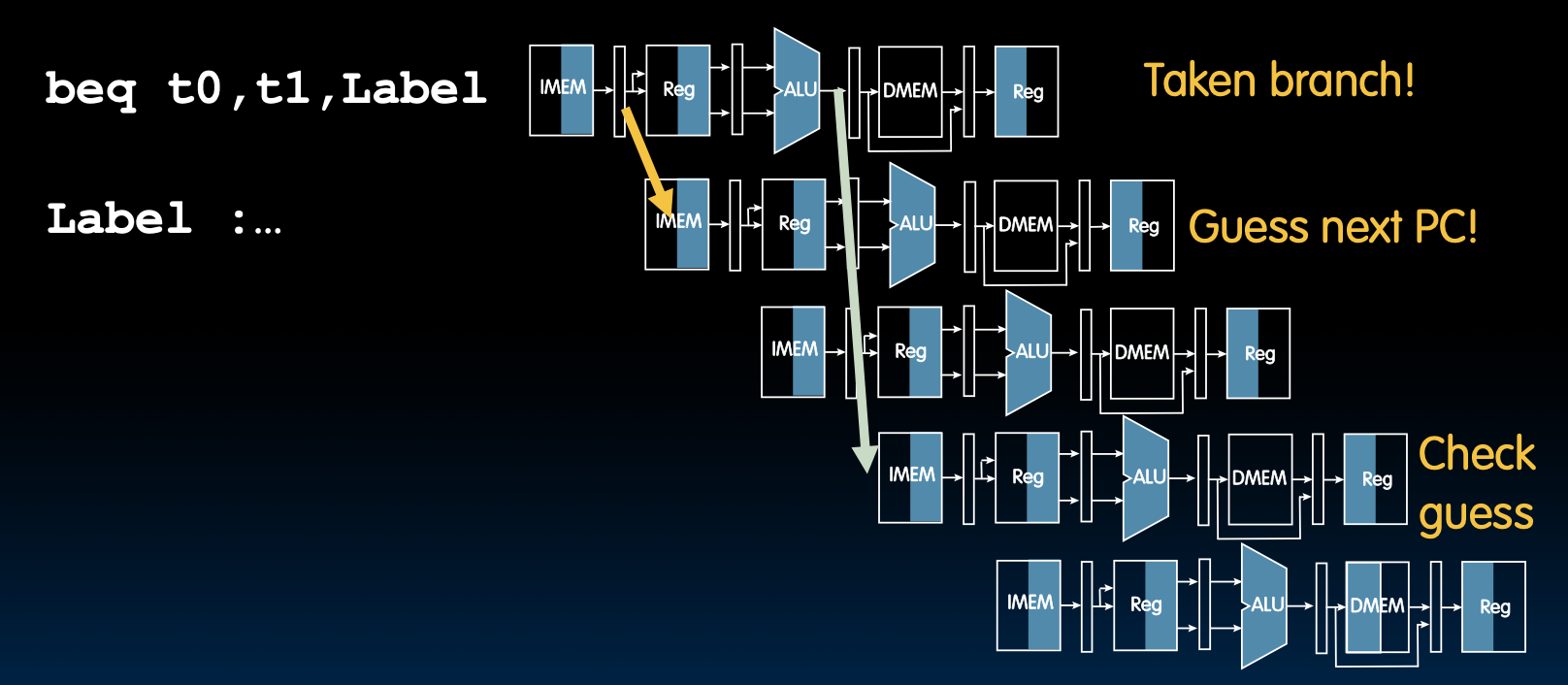
控制冒险:也称为分支冒险,由于取到的指令并不是所需要的,或者指令地址的流向不是流水线所预期的,导致正确的指令无法在正确的时钟周期内执行。
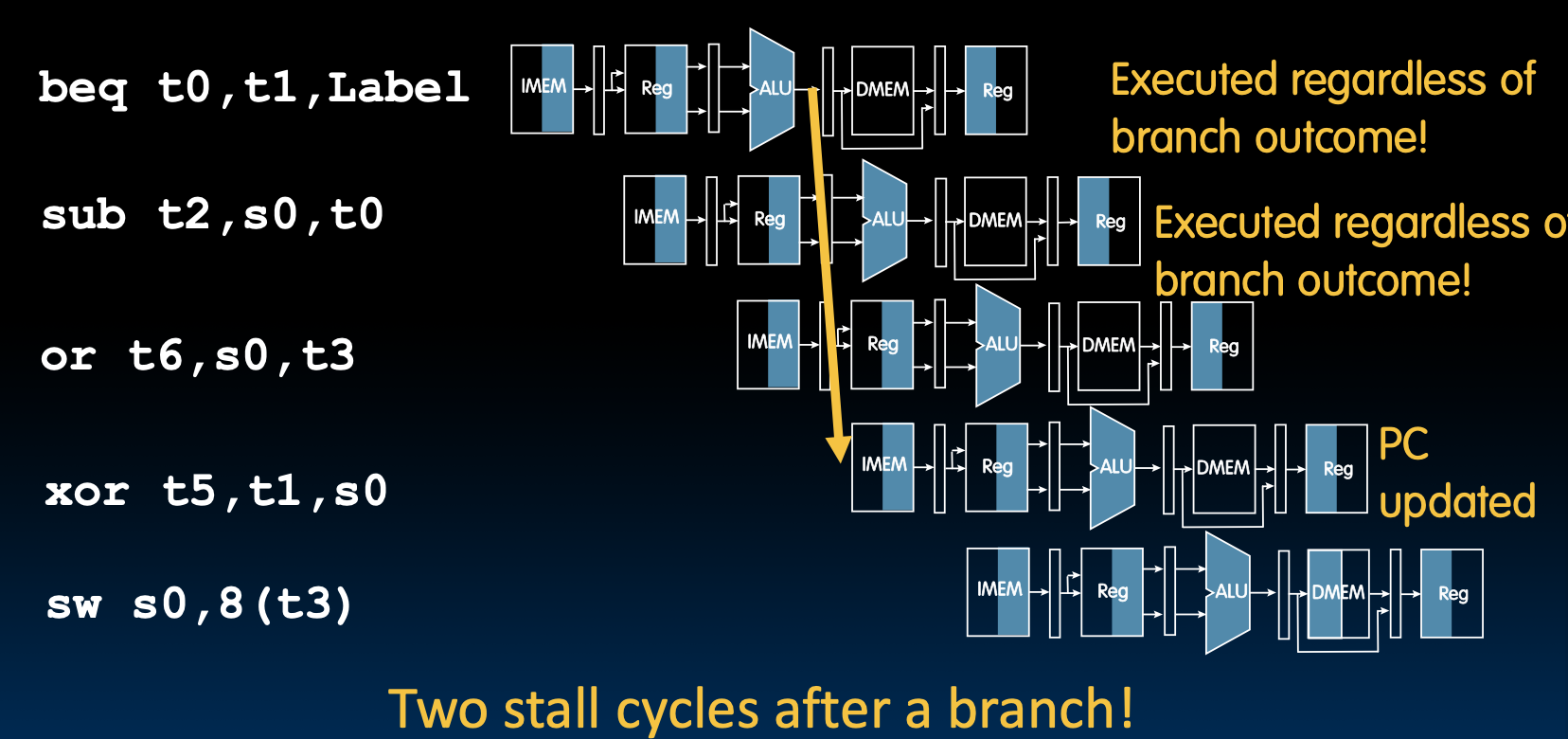
两个周期之后我们才知道beq到底需不需要跳转,所以beq后面的两条指令实际上不知道是否该不该执行。这就产生了控制冒险。所以,我们应该在条件转移指令后面stall两个周期。
让我们看看如何优化这个停顿的两个周期。
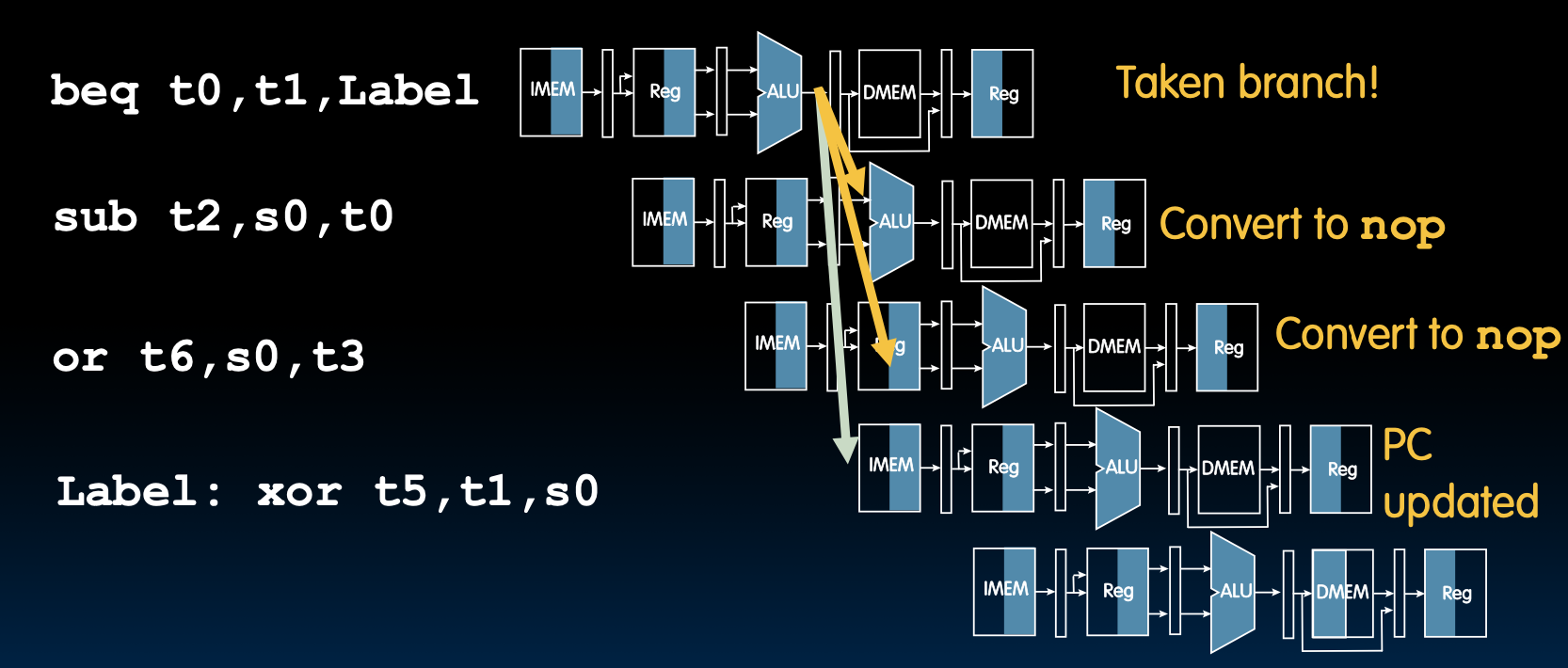
我们就假设他可以正常工作,如果假设正确,那么我们就节省了2个周期的停顿的时间,如果假设错误,就清楚流水线中错误的命令。这个假设称为分支预测
-
分支未采取:
- 分支后连续获取的指令是正确的。
-
分支或跳转已采取:
- 需要清除流水线中错误的指令。
所以我们有百分之五十的机会不需要停顿的。
让我们看看如何清楚错误的指令。
Kill Instructions after Branch if Taken
Reducing Branch penalities
实际上条件转移多用于循环,比如说100次循环,可能99次都不会转移,所以分支预测可以提高效率。
分支预测器有简单的也有复杂的,简单的只记录1位,简单的表示上次分支有没有转移。
Superscalar Processors
大概介绍了这些。
-
超标量处理器
-
多发射
-
乱序执行
