Implement copy-on write (hard)
cow(写时复制)机制不难,但是细节真的很容易出错TwT。不过做完这个lab也是收获满满,对虚拟内存的认识直接跨了一大步。
首先来介绍一下写时复制(copy on write)技术,懒得自己写了,直接摘抄大佬们的文章。
以下来自tzyt
在没有写时复制的系统中,调用 fork() 时,我们会把父进程的所有的内存都拷贝到子进程的空间,自然,这个耗时是巨大且不可接受的。
并且在实际应用中,fork() 时拷贝的大部分内存都时不会被用到的,比如,在 UNIX 中新建一个进程的通常会先调用 fork(),然后调用 exec()。那么原先复制过来的数据就全部没用了。
在 fork() 时,只有一种情况是需要复制内存的。就是写入数据时,如果父进程或子进程尝试往某个地址写入值,那么为了确保写入的这个值不会影响别的进程,我们需要复制这个页帧。
而写时复制就是这样的一个技术,我们会把父进程和子进程共享页帧的 PTE 标为不可写的。那么有任何一个进程尝试往这个页帧写入时,就会产生缺页错误。在 usertrap() 函数中,我们可以处理这样的情况,也就是把共享页帧复制一份给尝试写入的进程,这个被复制的页帧会被标记为可写的。
实现写时复制后,可能会有多个进程同时共享一个页帧,那么只有所有的进程都不需要这个共享页帧时,我们才能真正的释放这个页帧。
了解以上知识之后,我们就可以着手实现cow了。首先我们要修改/kernel/vm.c/uvmcopy()这个函数,这个函数在fork()的时候会被调用,用于复制父进程的页给子进程。但是此时,我们并不希望直接复制一份,因为这样会导致资源的浪费。只需要将父进程的物理页映射给子进程就好了。当需要对页进行读写操作的时候,再给这个cow页分配真正的物理内存(物理页)。先来更改uvmcopy()的映射逻辑。
//kernel/vm.c/uvmcopy()
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
// char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
*pte &= (~PTE_W); // 这里清除了写位,当需要对分页进行写入操作的时候
// 才会引起page fault从而进入usertrap()处理
*pte |= PTE_C // cow页标志,当遇到page fault的时候告诉内核
// 这是一个cow页引起的错误
flags = PTE_FLAGS(*pte);
// if((mem = kalloc()) == 0)
// goto err;
// memmove(mem, (char*)pa, PGSIZE);
if(mappages(new, i, PGSIZE, pa, flags) != 0){ //将pa直接映射
// kfree(mem);
goto err;
}
pgref_inc((void*)pa);
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
但是现在请思考一个问题,内核怎么知道遇到page fault的时候到底是真的出现了错误还是只是因为这是个cow页引起的?(看了注释,大家应该可以猜到,我们利用了PTE中保留的两位RSW位,利用其中一位来表示页是否为cow页。
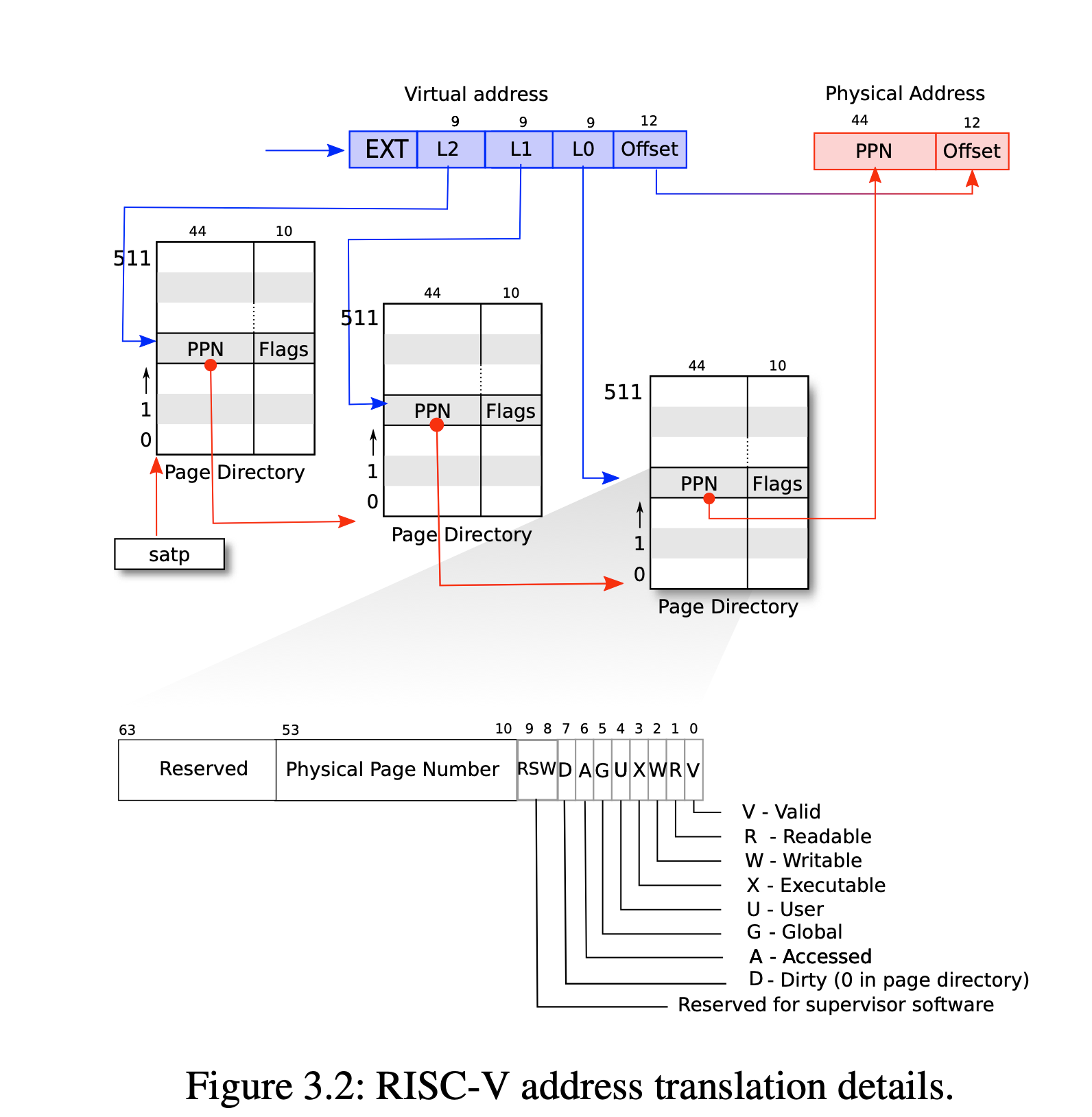
我们在kernel/riscv.h中加入如下定义
#define PTE_C (1L << 8) // 1 -> cow page
接着我们就要处理由于cow page引起的page fault了。首先,我们需要引起trap的原因是发生了page fault,其次,我们需要知道这是一个cow page引起的page fault(而不是由正常页错误引起的),那么我们如何知道陷入trap的原因是什么呢?查看riscv手册可以得知。
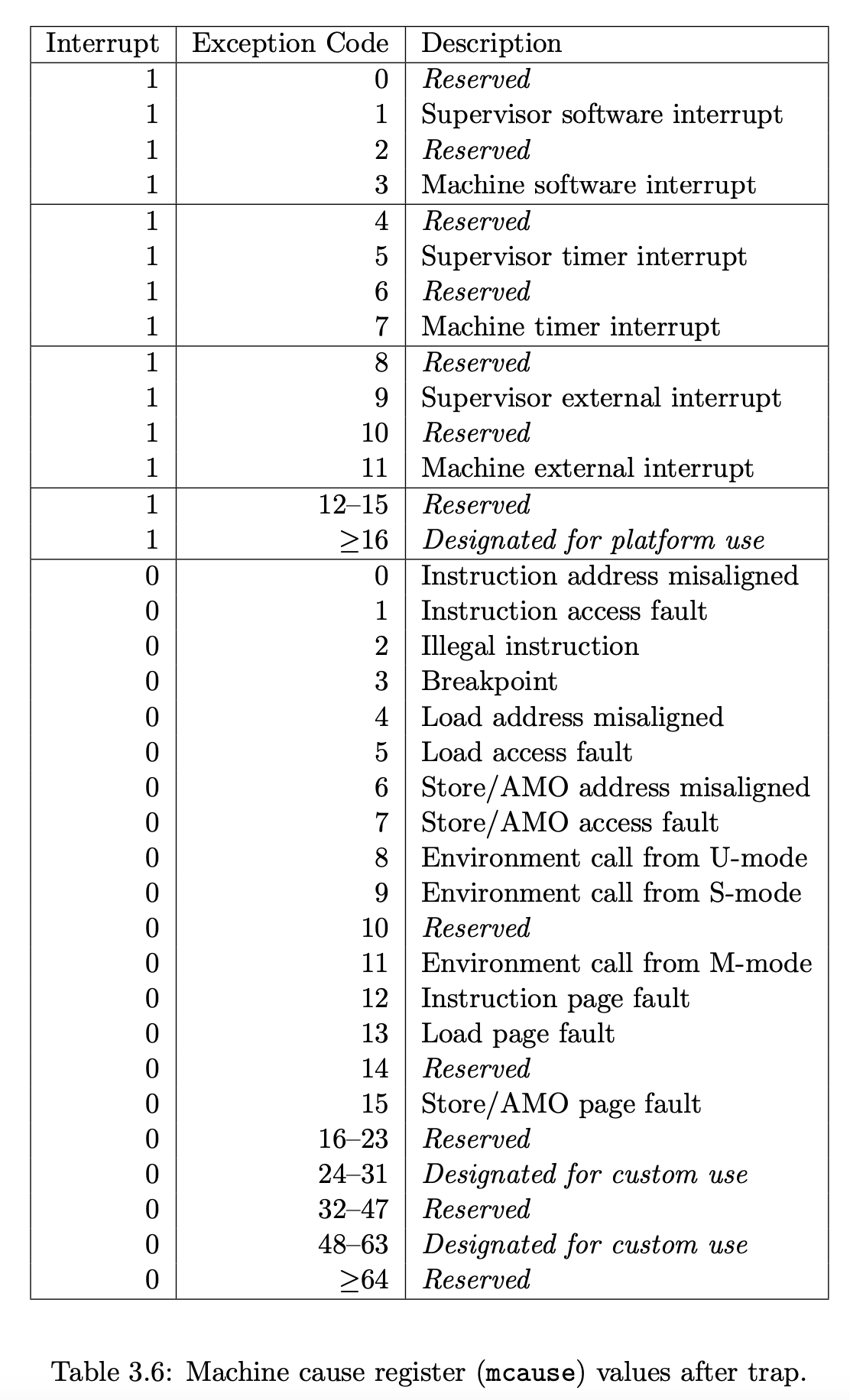
所以当发生页错误的时候,scause寄存器会被设置成15,然后我们还可以通过访问pte来得知页是否为cow page。那么我们就在usertrap()中加入如下逻辑
//kernel/trap.c/usertrap()
...
else if((which_dev = devintr()) != 0){
// ok
} else if (r_scause() == 15 && is_cow_page(p->pagetable, r_stval())) {
if (alloc_cow_page(p->pagetable, r_stval()) != 0) {
printf("usertrap(): alloc page for cow failed\n");
p->killed = 1;
}
} else {
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
p->killed = 1;
}
...
这里调用了两个函数,is_cow_page用于判断引起页错误的页面是否合法并且是个cow页,alloc_cow_page则用于为这个cow page分配真正的物理页(就是拷贝一份原来的引用页,然后改动一下pte位再重新映射回虚拟地址)
那么我们便要开始着手实现这两个逻辑。由于这两个函数涉及到虚拟内存,所以我选择在kernel/vm.c这里面定义。
//kernel/vm.c
int
is_cow_page(pagetable_t pagetable, uint64 va) {
if(va >= MAXVA)
return 0;
pte_t* pte = walk(pagetable, PGROUNDDOWN(va), 0);
if(pte == 0) // 如果这个页不存在
return 0;
if((*pte & PTE_V) == 0)
return 0;
if((*pte & PTE_U) == 0)
return 0;
return ((*pte) & PTE_C); // 有 PTE_C 的代表还没复制过,并且是 cow 页
}
int
alloc_cow_page(pagetable_t pagetable, uint64 va) {
uint64 pa;
char* mem;
pte_t* pte;
int flags;
va = PGROUNDDOWN(va); // 对齐页
pte = walk(pagetable, va, 0);
flags = PTE_FLAGS(*pte);
flags ^= PTE_C;
flags |= PTE_W;
pa = walkaddr(pagetable, va);
mem = kalloc();
if (!mem) {
printf("alloc_cow_page(): kalloc failed.\n");
return -1;
}
memmove(mem, (void*)pa , PGSIZE);
uvmunmap(pagetable, va, 1, 1); // 这里do_free设置为1,让这个函数调用kfree函数,使之页面引用变少
if (mappages(pagetable, va, PGSIZE, (uint64)mem, flags) < 0) {
printf("alloc_cow_page(): map failed");
kfree(mem);
return -1;
}
return 0;
}
记住重新映射之前要unmap掉之前的引用页再重新map!
好了,我们现在完成了子进程创建时的懒拷贝了,但是有个问题,假如被引用的页面被free掉了怎么办?!那我其他进程map过去的页面怎么办?所以很自然的想到,在一个页面不被任何PTE引用的时候就释放它。所以我们需要为物理页面加上一个counter,用于计数其被引用的次数。我们用物理页的地址除以PGSIZE的到数组索引,通过索引位的值就是引用的次数
在kernel/kalloc.c下定义,为了防止竞态(race condition)导致的内存泄漏,我们还需要定义一个锁。
#define PPAGEMAX ((PHYSTOP - KERNBASE) / PGSIZE)
#define PG2INDEX(pa) (((uint64)pa - KERNBASE )/ PGSIZE)
#define PGREF(pa) pgrefarr[PG2INDEX(pa)] // 主要用这个,直接传pa就能访问数组了
int pgrefarr[PPAGEMAX];
struct spinlock pgreflock;
里面的 PHYSTOP 和 KERNBASE 代表着内存物理地址的起始和结束,所以我们要把 pa 减去 KERNBASE 后再除以 PGSIZE。
我刚开始还很疑惑,我们在内核中开了这个数组,是存在哪里的。其实可以看下 kinit() 的实现:
void
kinit()
{
initlock(&kmem.lock, "kmem");
freerange(end, (void*)PHYSTOP); // 注意这里
}
这里的 end 是上图中 Free memory 的开始,定义在 kernle.ld 中,也就是说,对于内核自己的数据和代码(包括这个数组),是存在 kernel text 和 kernel data 中的,而 kalloc() 函数只会去分配 end ~ PHYSTOP 中的内存。当数组被分配进kernel data的时候,end也会随之增加。
然后修改或增加以下函数
//kernel/kalloc.c
void
kinit()
{
initlock(&kmem.lock, "kmem");
initlock(&pgreflock, "pgref");
freerange(end, (void*)PHYSTOP);
}
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
acquire(&pgreflock);
if(--PGREF(pa) <= 0) {
// 当页面的引用计数小于等于 0 的时候,释放页面
// Fill with junk to catch dangling refs.
// pa will be memset multiple times if race-condition occurred.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
release(&pgreflock);
}
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r)
{
memset((char*)r, 5, PGSIZE); // fill with junk
PGREF(r) = 1;
}
return (void*)r;
}
void
pgref_inc(void* pa) {
acquire(&pgreflock);
PGREF(pa)++;
release(&pgreflock);
}
总结
逻辑简单但是坑很多,差不多写了10小时,加上查阅资料的时间肯定还不止,而且博主写到这里的时候并没有了解太多并发的知识,导致一开始根本不知道要用锁。
参考文章
MIT 6.S081 Lab5 Copy-On-Write Fork

https://shorturl.fm/gw03x