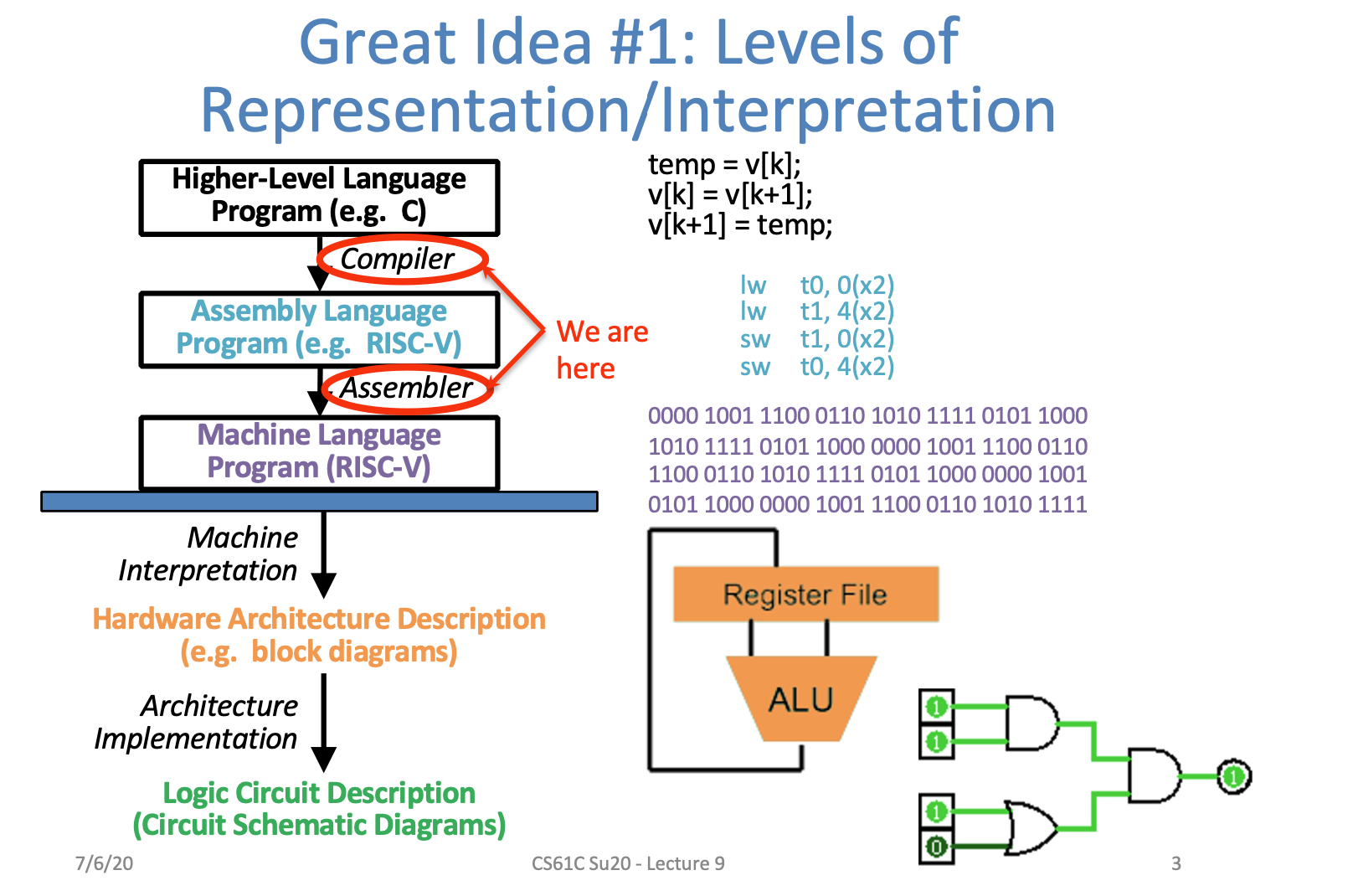
Translation vs. Interpretation
怎么运行一个用源码写成的程序?
- Interpreter:用源码直接执行程序
解释器是一种程序,它可以逐行读取并直接执行源语言程序。解释器不生成任何中间代码或目标代码,而是直接解析并执行源代码。
- Translator:将源码用别的语言转换成相同的程序
Interpreter
-
当你不在乎执行效率的时候可以直接Interpret一个高级程序语言
-
将代码转换成更低级的语言可以增加程序的性能
-
通常来说,编写一个解释器是更容易的
-
因为解释器更接近高级语言,所以他可以提供更好的错误信息
-
解释器提供了基于指令集的独立性,因为它可以运行在任何机器上
Translator
-
翻译/编译过的代码总是会更高效,因此会获得更高的性能
- 这点很重要,特别是对于操作系统来说
-
翻译/编译有助于隐藏程序源码
C Translation
回忆一下,在c语言中有个很关键的内容——可以将文件分开编译,然后在合并成一个可执行文件
回想一下我们可以在文件之间访问到什么?
-
函数
-
全局变量
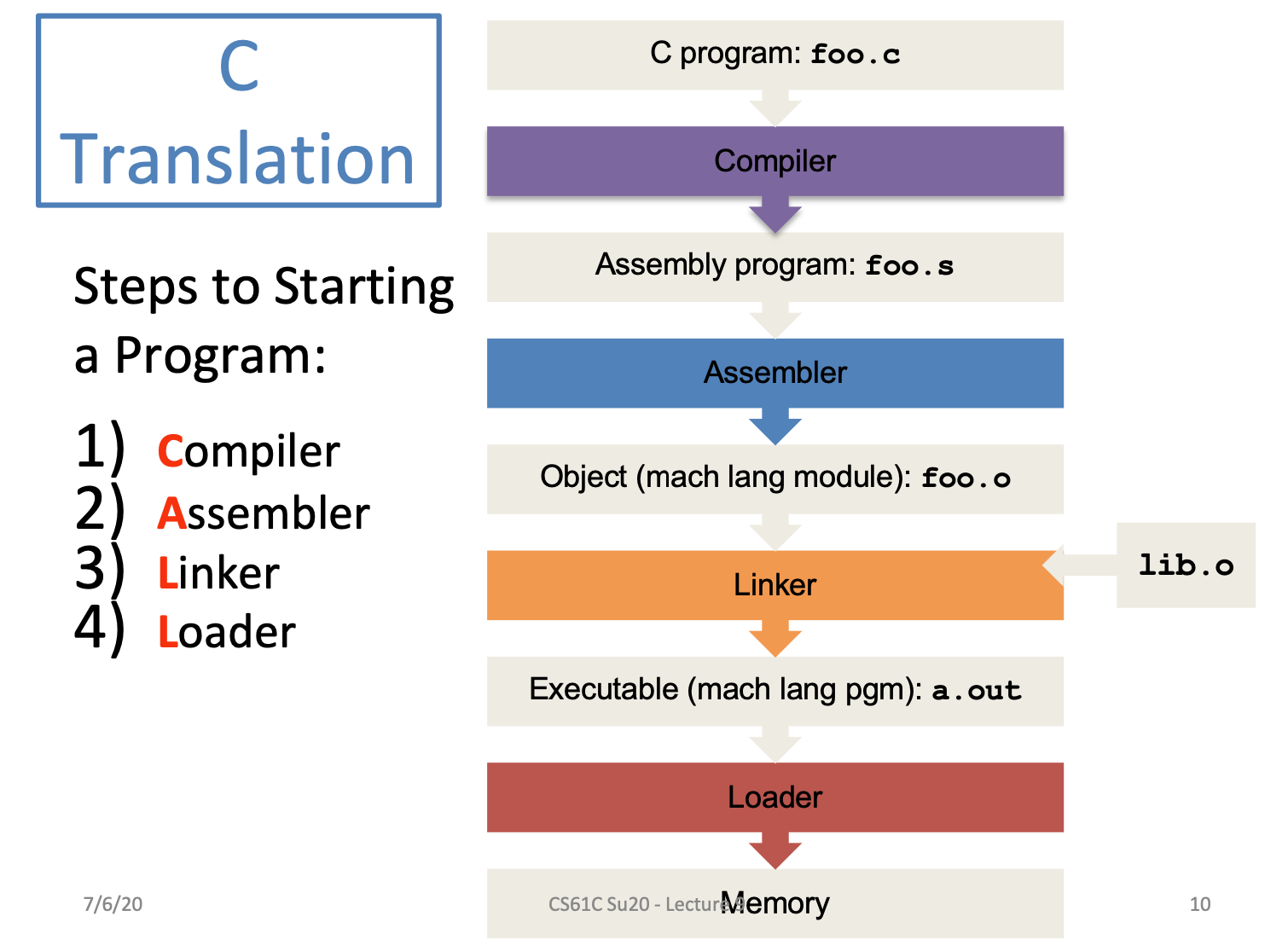
Compiler
输入高级语言代码(Higher-level language HLL),输出汇编语言代码
-
注意,输出的代码可能会含有伪指令
-
在实际的编译过程中,通常会有一个预处理步骤来处理源代码中的预处理指令(
#directives),这些指令通常涉及头文件的包含、宏定义等。预处理器会根据这些指令对源代码进行修改,然后再交给编译器处理。虽然这是一个重要的步骤,但它本身并不特别复杂或令人兴奋。
Compilers Are Non-Trivial
CS164就是专门介绍编译器的课程,但是在61C中我们不会提到太多细节,如果你感兴趣,可以看看这个(https://www.sigbus.info/how-i-wrote-a-self-hosting-c-compiler-in-40-days)
一些复杂的任务示例
-
2 + 3 * 4-> 运算符的优先级 -
a = b = c;,编译器需要知道赋值运算符=的结合方式。在这里,赋值运算符从右向左结合,因此先执行b = c,再执行a = b。如果b和c的值相同,则a也会获得相同的值 -
if (a) { if (b) { … /*long distance*/ … } } }检测大括号的匹配等问题
Assembler
Assembler
Input/Output: Optimised RISC-V/assembly (*.s) ⇒ object file (*.o)
输入.s
-
汇编语言代码:
- 汇编器的输入是用某种特定架构的汇编语言编写的源代码文件,例如对于 RISC-V 架构,输入文件可能是
foo.s。
- 汇编器的输入是用某种特定架构的汇编语言编写的源代码文件,例如对于 RISC-V 架构,输入文件可能是
输出.o
文件头 (File Header)
- 大小和位置:文件头提供了关于文件其他部分(如文本段、数据段等)的大小和位置的信息。
文本段 (Text Segment)
- 机器码:文本段包含了程序的机器码指令。这些指令是汇编语言源代码经过汇编后的结果。
数据段 (Data Segment)
- 静态数据:数据段包含了程序的初始化数据和常量,这些数据通常是在程序运行之前就确定好的。这些数据以二进制形式存储在文件中。
符号表 (Symbol Table)
- 标签和相对地址:符号表列出了程序中的所有符号(例如函数名、变量名等)及其对应的相对地址。这些信息对于链接过程非常重要。
重定位表 (Relocation Table)
- 需要定位的值:重定位表包含了所有需要在链接过程中更新地址的条目。这些条目可以是内部的也可以是外部的。
调试信息 (Debugging Information)
- 调试元数据:调试信息可以帮助开发人员在调试程序时了解源代码和编译后的机器码之间的对应关系。这些信息通常包括源文件名、行号、变量名等。
读取并使用指令
替换伪指令
生成机器码
Assembler Directives
.text
- 用途:声明接下来的指令应该被放入用户文本段(通常是包含可执行代码的部分)。
.data
- 用途:声明接下来的数据定义应该被放入用户数据段(通常是用来存放初始化数据和常量的部分)。
.asciiz <str>
- 用途:将字符串
<str>存储到内存中,并以空字符 (\0) 结尾。
.word <w1>…<wn>
-
用途:将一系列的 32 位值
<w1>…<wn>存储到连续的内存位置中。 -
Pseudo-instruction Replacement
| Pseudo | Real |
|---|---|
| mv t0, t1 | addi t0, t1, 0 |
| neg t0, t1 | sub t0, zero, t1 |
| li t0, imm | addi t0, zero, imm |
| not t0, t1 | xori t0, t1, -1 |
| beqz t0, loop | beq t0, zero, loop |
| la t0, str | lui t0, str[31:12] <br>addi t0, t0, str[11:0] <br>OR <br>auipc t0, str[31:12] <br>addi t0, t0, str[11:0] |
Producing Machine Language
simple case
执行简单的命令,例如算数指令或者是逻辑指令等,所有必备的信息都会直接包含在指令中。但是如果是条件转移指令或事跳转指令的话又该怎么办呢?这两个指令都依赖于相对地址。
那么关于branches或是jumps指令呢
一旦伪指令被替换成真实的指令,我们就知道我们需要跳过多少个指令了,所以这不是问题。
"Forward Reference" Problem
Forward Reference(向前引用):指的是branch指令引用了一个在这段代码前面的标签(未定义的标签)
如果未定义,我们怎么知道地址呢?我们可以两次扫描程序(Two Passes Overview)
Two Passes Overview
Pass 1:
-
将遇到的伪指令展开
-
记住标签的位置
-
将空行以及注释去掉
-
错误检查
Pass 2:
-
用标签的位置生成相对地址(用于branch和jumps)
-
输出
object file,一个二进制指令集合
关于PC-relative jump(jal)和branches(beq,bne)呢?
-
j offset是个伪指令,它会被扩展成jal zero, offset -
仅需计算目标和跳转之间的指令半字数,即可确定偏移量:position-independent code(PIC)计算相对地址,所以是position-independent的
Symbol Table & Relocation Table
- 如果我们需要跳转到外部标签该怎么办?
-
我们需要知道标签最终的地址
-
不管这个标签有没有提前定义,如果我们不知道指令在内存中的地址,我们都无法将其转化成机器指令
- 关于数据引用呢?
-
la有时候会被分成lui和addi(在PC-relative中使用auipc/addi)(这里为什么要提la?因为这个命令就是关于数据引用的) -
这需要数据的完整32位地址。它完全不依赖PC。所以我们引入了符号表和重定位表的概念。在程序编译或汇编阶段,如果遇到数据引用,就需要生成这样的指令序列来构建完整的32位地址。由于此时并不知道最终的数据地址是多少(因为数据可能位于其他文件中,且地址取决于链接阶段的结果),因此需要创建重定位表来记录这些未知地址,并在链接阶段通过重定位来填充实际的地址值。
符号表 (Symbol Table)
Symbol Table列出了可能会被使用的“东西”,他们可能是一个Label,或是一个Data
作用
-
内部使用:在编译或汇编过程中,符号表用于存储当前文件中的符号及其相关信息,以便处理前向引用。
-
跨文件引用:其他文件可以使用该符号表来替换它们自己的外部引用。
这些“东西”都包括哪些
-
标签 (Labels):函数调用中使用的标签。
-
数据 (Data):任何存储在
.data段中的数据,包括变量,这些变量可以在不同文件之间共享。
解决问题
- 前向引用问题:有时候,一个标签(如函数名)会被引用,但在引用时它还没有被定义。通过在符号表中记录这些标签,就可以在链接过程中解决这些问题。
重定位表 (Relocation Table)
当我们用一些使用绝对地址的命令时,比如jal,jalr或是la,但是我们此时并不知道我们需要的绝对路径,所以重定位表就相当于记录下这些位置,当链接完成之后,再去填写这些地址。
它主要用来记录那些在编译或汇编阶段无法确定其确切地址的符号或数据的位置。在链接阶段,链接器会使用这些信息来更新这些符号或数据的实际地址。
重定位表的作用
-
记录未知地址:在编译或汇编阶段,某些指令或数据的地址是未知的,这些信息会被记录在重定位表中。
-
解决外部引用:对于外部定义的符号或数据(例如,在其他文件或库中定义的),重定位表也会记录这些引用。
-
链接时更新地址:链接器会使用重定位表来更新所有未知地址,确保它们指向正确的内存位置。
重定位表的内容
-
绝对标签跳转:任何使用
jal或jalr指令跳转到的绝对标签都会被记录下来。 -
内部标签:有时也会记录内部定义的标签,尤其是当这些标签的地址在编译或汇编阶段不确定时。
-
外部标签:总是记录外部定义的标签,包括来自库文件中的标签。
-
加载指令:使用
la(Load Address)指令加载的符号也会被记录下来,特别是当这个符号是由LUI指令定义的时候。 -
静态数据段的数据:在静态数据段(
.data段)中的任何数据都会被记录,因为这些数据的地址在链接前也是未知的。
Linker
Linker
Object files(*.o)->excutable(*.out)
Input:目标代码文件(Object code file),信息表(information tables)(e.g. foo.o,lib.o)
Output:可执行的代码(e.g. a.out)
Linker的作用:将多个目标代码文件整合成单个可执行文件(这个过程称为链接“Linking”)
好处:可以单独编译文件,更改一个文件就不需要重新编译整个程序了。
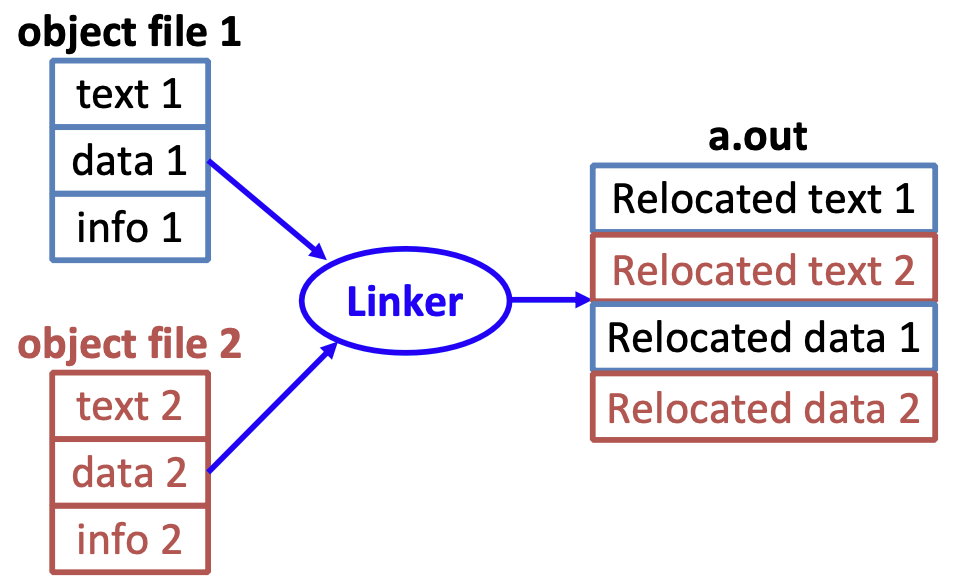
Linker Execution
-
将每个
.o文件的文本段(text segment)都放在一起 -
将每个
.o文件的数据段(data segment)都放在一起,放在文本段的后面 -
解决了引用问题:查看重定位表,然后处理上面的每一项(i.e. 将绝对地址填进去)
可执行文件 (.out)
内容
-
Header:头部包含了一些元数据,如文本段和数据段的大小等信息。
-
文本段和数据段的大小:这些信息用于描述程序的结构,帮助操作系统了解如何加载和运行程序。
-
为什么不需要文本段和数据段的位置?:在可执行文件中,文本段和数据段的位置通常由操作系统决定。操作系统在加载程序时会为这些段分配内存,并根据头部信息来确定各段的大小。因此,可执行文件本身不需要显式地指定这些段的确切位置。
-
-
文本段和数据段:在链接完成后,所有目标文件(
.o文件)中的文本段(包含机器码指令)和数据段(包含初始化数据)都被合并到一起,形成了可执行文件的主体。
Four Types of Addresses
有四种类型的地址
- PC-Relative Addressing (
beq,bne,jal;auipc/addi)- 不需要重定位(PIC:Position-Independent Code)
- Absolute Function Address(
auipc/jalr)- 总是需要重定位
- External Function Reference(
auipc/jalr;jal ext_label)- 总是需要重定位
- Static Data Reference(Often
lui/addi)- 总是需要重定位
Resolving References
Linker 假设文本段的起始位置在0x10000这里(64位RISCV在0x400000000)
Linker知道文本段和代码段的长度(all the information in the .info,in the information file form each of those .o files),还有顺序,所以它可以计算出每个Label(internal or external)和被引用Data的绝对地址
Q: How can the linker assume the code will be loaded to the same address every time?
A: Later this semester: virtual memory!
To resolve references
-
Search for reference (data or label) in all “user” symbol tables
- 链接器首先会在用户提供的代码(源文件编译产生的目标文件)中查找所需的Symbol(数据或标签)。
- 这些Symbol可能是在同一文件内定义的,也可能是在其他文件中定义但在此文件中引用的。
-
If not found, search library files (e.g. printf)
- 如果在用户提供的代码中没有找到所需的Symbol,链接器会继续在标准库文件中查找。
- 例如,当你的程序调用
printf函数时,链接器会在标准库中查找该函数的实现。
-
Once absolute address is determined, fill in the machine code appropriately
- 一旦找到了Symbol的定义,并确定了其绝对地址,链接器就会更新机器码以指向正确的地址。
Static vs Dynamically Linked Libraries
这里说到了静态链接库和动态链接库
Static Linked
如果用静态链接库的话,就是将库整个塞进可执行文件里,如果现在库更新了,我们想要用新的库,就需要重新编译,以此来把库塞进去。这就很麻烦,内置库想要更新就得重新编译。这就是静态链接。
Dynamically Linked
动态链接模式,在运行的时候,将库链接进来,在Windows中称为DLL(Dynamically linked library)。
优势:
-
程序体积更小
-
执行两个程序的时候可能需要更少的内存(因为它们可能共享一个库)
-
更新库的时候更方便,因为不像Static Linked一样需要重新编译,只需要替换掉原来的旧库就好了
劣势:
-
运行时需要更多的时间,用于链接到库
-
除了可执行文件以外,还需要库来支持,如果库损坏了,可执行文件也运行不了
动态链接是发生在机器码层次,大概就是腾出一个空间,把库塞进去再运行
Loader
将磁盘中的可执行文件加载到内存中
读取可执行文件的header,以便于明确文本段和数据段的size
为程序创建足够大的新地址空间(虚拟内存那一章会提到,实际上我并没有给那么大的空间,但是假设我给了),以容纳文本和数据段,以及堆栈段。
将可执行文件中的指令和数据复制到一块新的内存地址中
将值(command-line arguments)传进栈中
初始化寄存器
将参数从栈上复制到寄存器中(i.e. 比如在main中,argc复制到a0,argv复制到a1),设置PC
