通过内存映射文件的方式加快访问速度。
感觉初见提示和之前的speed up系统调用有点相似,需要在内存中找到一块地方做映射。
首先我们要注册系统调用。将以下代码添加进user/user.h中。
void* mmap(void *addr, uint64 length, int prot, int flags, int fd, uint64 offset);
int munmap(void *addr, uint64 length);
mmap
mmap会增加文件引用计数,使得文件不会被关闭
我们需要在进程地址空间中找到一块地方来存放vma结构体,以便实现文件映射。
查阅 the xv6 book,可以看到 xv6 对用户的地址空间的分配中,heap 的范围一直从 stack 到 trapframe。由于进程本身所使用的内存空间是从低地址往高地址生长的(sbrk 调用)。
为了尽量使得 map 的文件使用的地址空间不要和进程所使用的地址空间产生冲突,我们选择将 mmap 映射进来的文件 map 到尽可能高的位置,也就是刚好在 trapframe 下面。并且若有多个 mmap 的文件,则向下生长。
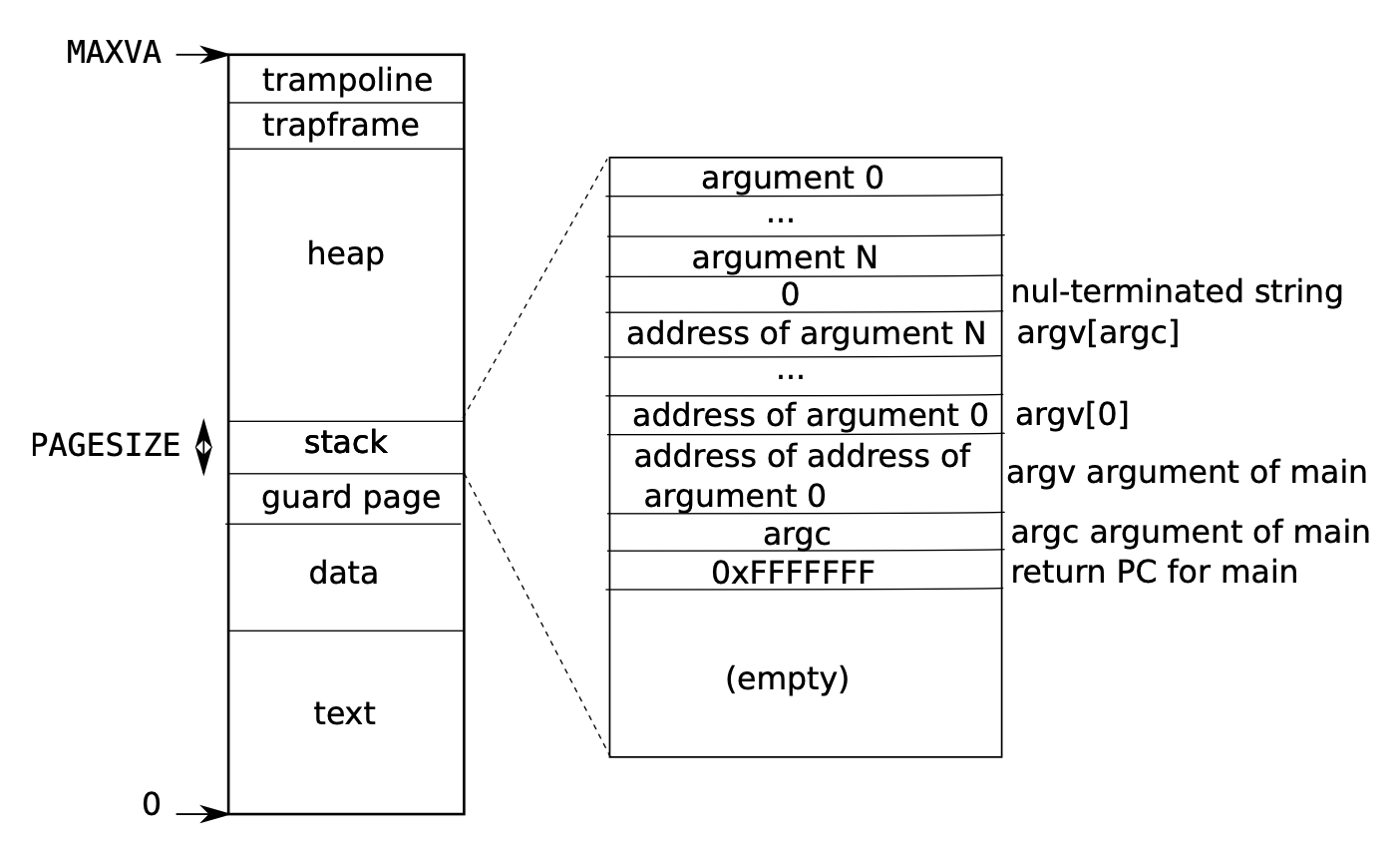
因为我们要实现懒加载,所以在mmap中我们不需要分配物理内存的,只需要将需要映射的信息存在proc结构体内的vma结构体里,当出现访问页错误的时候,我们再根据vma里面的信息,真正的分配内存就好了。同时我们要处理一个奇怪的情况,如果尝试将一个只读打开的文件映射为可写,并且开启了回盘(MAP_SHARED),则 mmap 应该失败。否则回盘的时候会出现回盘到一个只读文件的错误情况。
于是我们可以写出如下代码
//kernel/sysfile.c
uint64
sys_mmap(void)
{
uint64 size; // 映射过去的字节数,可能与文件大小不一样
int prot; // 指示内存是否应映射为可读、可写,以及/或者可执行的
int flags; // flags要么是MAP_SHARED(映射内存的修改应写回文件),要么是MAP_PRIVATE(映射内存的修改不应写回文件)
int fd; // 映射的文件的打开文件描述符
if (argaddr(1, &size) != 0 || argint(2, &prot) != 0 || argint(3, &flags) != 0 || argint(4, &fd) != 0) {
return -1;
}
struct proc* p = myproc();
struct vma* v = 0;
struct file* file;
file = p->ofile[fd];
if(!file->writable && (prot & PROT_WRITE) && (flags & MAP_SHARED))
return -1;
size = PGROUNDUP(size); // 为了释放的时候好释放
struct vma *vsearch = p->vma;
int vma_find = 0;
uint64 vend = MMAPEND;
for (int i = 0; i < VMA_LENGTH; i++) {
if (vsearch[i].valid == 0) {
// 找到第一个无效的 vma 位置
if (vma_find == 0) {
vma_find = 1;
v = &vsearch[i]; // 指向第一个空闲的 vma 位置
v->valid = 1;
}
} else if (vsearch[i].addr < vend) {
// 更新 vend,使它指向未使用空间的最低有效地址
vend = PGROUNDDOWN(vsearch[i].addr);
}
}
// 返回找到的 vma 或 vend 值的结果
if(v == 0)
{
printf("cant mmap more file\n");
return -1;
}
v->addr = vend - size;
v->f = file;
v->flags = flags;
v->prot = prot;
v->offset = 0;
v->size = size;
filedup(v->f);
return v->addr;
}
这样我们就完成了写入vma信息但并不真正分配内存,当我们需要访问这段空间的时候,由于并没有分配,所以会进入到trap,所以我们修改trap来处理。
//kernel/trap.c
...
else if((which_dev = devintr()) != 0){
// ok
} else if ((r_scause() == 13 || r_scause() == 15)) {
if (!lazy_load_mmap(r_stval())) {
goto unexpectedscause;
}
}else {
unexpectedscause:
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
p->killed = 1;
}
...
如果我们接收到一个由page fault引发的tarp,我们就进行加载页。因为我们是在trap.c里面调用这个懒加载函数,所以我们需要去defs.h里面注册一下。
//kernel/sysfile.c
int
lazy_load_mmap(uint64 va)
{
// 根据访问到的无效地址寻找对应的vma,并为其分配物理内存。
struct proc *p = myproc();
struct vma *v;
// 寻找va对应地址
v = find_vma(p, va);
if(v == 0)
{
return 0; // 引发trap的位置并不是vma区,直接返回
}
// 如果是vma区,我们则需要分配物理内存,并将虚拟内存里的数据映射过去,此外,还需要从磁盘读写数据(写到这句话的时候我突然蒙了,我要往哪读数据???答案是,我们往分配的物理内存写入数据,并将其映射会虚拟地址空间)
char* mem;
mem = kalloc();
if(mem == 0) return -1;
memset(mem, 0, PGSIZE);
begin_op();
ilock(v->f->ip);
readi(v->f->ip, 0, (uint64)mem, PGROUNDDOWN(va - v->addr), PGSIZE);
// 为啥我们需要这个偏移量
// 因为这个偏移量就是我们的开始位置,文件并不总是从开头读入,PGROUNDDOWN(va - v->addr)代表文件拷贝时要跳过多少个页帧
iunlock(v->f->ip);
end_op();
// set appropriate perms, then map it.
int perm = PTE_U | PTE_V;
if(v->prot & PROT_READ)
perm |= PTE_R;
if(v->prot & PROT_WRITE)
perm |= PTE_W;
if(v->prot & PROT_EXEC)
perm |= PTE_X;
if(mappages(p->pagetable, va, PGSIZE, (uint64)mem, PTE_R | PTE_W | PTE_U) < 0) {
panic("vmalazytouch: mappages");
}
return 1;
}
注意sys_mmap应该放在sysfile.c里面,因为头文件齐全,如果放在在sysproc.c应该需要手动添加头文件。
munmap
Q:在mmap的时候将虚拟内存中的内容直接按一个页一个页的形式加载到内存中了,为什么munmap的时候不能直接释放一个页呢,我们在之前mmap的时候size是向页顶对齐的,如果size大于一个页,我们释放多个页,小于一个页,直接释放当前页不行吗
我就算mmap过去的size小于一个页,但是我kalloc 以及mappages的时候都是按照PGSIZE操作的,为什么还要考虑这些情况呢
A:可能是因为有些unmap并不是需要完整释放一个PGSIZE,而是只unmap一部分。这样又引出了一个新的疑问
Q:我们访问数据的时候 不会因为消失了一段数据而导致计算机不知道这是什么而出错的情况吗
A:假设映射的地址是从 v->vastart 开始,大小为 v->sz。如果 munmap 的起始地址在 vastart 之后,且结束地址在 vastart + sz 之前,就会出现一个“洞”,这样会导致在 vma 的范围中间有一块空的内存区域。
操作系统一般不允许这样的“挖洞”操作,因为它会导致 vma 不连续,给后续的内存访问管理带来复杂性。因此,munmap 检测到这种情况时会直接返回错误。
lab提示我们可以使用uvunmap来完成munmap,但是实际上我们的munmap逻辑更加复杂,还需要考虑到写回磁盘的情况。参考大佬的博客可知
这里首先通过传入的地址找到对应的 vma 结构体(通过前面定义的 findvma 方法),然后检测了一下在 vma 区域中间“挖洞”释放的错误情况,计算出应该开始释放的内存地址以及应该释放的内存字节数量(由于页有可能不是完整释放,如果 addr 处于一个页的中间,则那个页的后半部分释放,但是前半部分不释放,此时该页整体不应该被释放)。
下面是大佬写的一段质量很高的代码,比如nummap我觉得实现的非常巧妙,通过大小来判断是否要释放页
// kernel/sysfile.c
uint64
sys_munmap(void)
{
uint64 addr, sz;
if(argaddr(0, &addr) < 0 || argaddr(1, &sz) < 0 || sz == 0)
return -1;
struct proc *p = myproc();
struct vma *v = findvma(p, addr);
if(v == 0) {
return -1;
}
if(addr > v->vastart && addr + sz < v->vastart + v->sz) {
// trying to "dig a hole" inside the memory range.
return -1;
}
uint64 addr_aligned = addr;
if(addr > v->vastart) {
addr_aligned = PGROUNDUP(addr);
}
int nunmap = sz - (addr_aligned-addr); // nbytes to unmap
if(nunmap < 0)
nunmap = 0;
vmaunmap(p->pagetable, addr_aligned, nunmap, v); // custom memory page unmap routine for mmapped pages.
if(addr <= v->vastart && addr + sz > v->vastart) { // unmap at the beginning
v->offset += addr + sz - v->vastart;
v->vastart = addr + sz;
}
v->sz -= sz;
if(v->sz <= 0) {
fileclose(v->f);
v->valid = 0;
}
return 0;
}
// kernel/vm.c
#include "fcntl.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "file.h"
#include "proc.h"
// Remove n BYTES (not pages) of vma mappings starting from va. va must be
// page-aligned. The mappings NEED NOT exist.
// Also free the physical memory and write back vma data to disk if necessary.
void
vmaunmap(pagetable_t pagetable, uint64 va, uint64 nbytes, struct vma *v)
{
uint64 a;
pte_t *pte;
// printf("unmapping %d bytes from %p\n",nbytes, va);
// borrowed from "uvmunmap"
for(a = va; a < va + nbytes; a += PGSIZE){
if((pte = walk(pagetable, a, 0)) == 0)
continue;
if(PTE_FLAGS(*pte) == PTE_V)
panic("sys_munmap: not a leaf");
if(*pte & PTE_V){
uint64 pa = PTE2PA(*pte);
if((*pte & PTE_D) && (v->flags & MAP_SHARED)) { // dirty, need to write back to disk
begin_op();
ilock(v->f->ip);
uint64 aoff = a - v->vastart; // offset relative to the start of memory range
if(aoff < 0) { // if the first page is not a full 4k page
writei(v->f->ip, 0, pa + (-aoff), v->offset, PGSIZE + aoff);
} else if(aoff + PGSIZE > v->sz){ // if the last page is not a full 4k page
writei(v->f->ip, 0, pa, v->offset + aoff, v->sz - aoff);
} else { // full 4k pages
writei(v->f->ip, 0, pa, v->offset + aoff, PGSIZE);
}
iunlock(v->f->ip);
end_op();
}
kfree((void*)pa);
*pte = 0;
}
}
}
// kernel/sysfile.c
// find a vma using a virtual address inside that vma.
struct vma *findvma(struct proc *p, uint64 va) {
for(int i=0;i<NVMA;i++) {
struct vma *vv = &p->vmas[i];
if(vv->valid == 1 && va >= vv->vastart && va < vv->vastart + vv->sz) {
return vv;
}
}
return 0;
}
我的实现
//kernel/sysfile.c
uint64
munmap(uint64 addr, uint64 size)
{
// 找到地址范围的VMA并取消映射指定页面(提示:使用uvmunmap)。如果munmap删除了先前mmap的所有页面,它应该减少相应struct file的引用计数。如果未映射的页面已被修改,并且文件已映射到MAP_SHARED,请将页面写回该文件。
struct proc *p = myproc();
struct vma *v = find_vma(p, addr);
// 接下来判断是否有挖洞区,如果挖洞了,就直接return -1
if (addr > v->addr && addr < v->addr + v->size)
{
return -1;
}
mmap_write_back(p->pagetable, addr, size, v);
if (addr == v->addr)
{
v->addr += size;
}
v->size -= size;
if(v->size <= 0)
{
fileclose(v->f);
v->valid = 0;
}
return 1; // 代表释放成功
}
uint64
sys_munmap(){
// int munmap(void *addr, size_t length);
uint64 addr,size;
if( argaddr(0,&addr) || argaddr(1,&size) ) return -1;
return munmap(addr, size);
}
//kernel/vm.c
#include "fcntl.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "file.h"
#include "proc.h"
int
mmap_write_back(pagetable_t pt,uint64 va, uint64 size, struct vma* vma)
{
// 把带脏位的页帧写回文件中,并且取消映射
// 写回的是 src_va 开始的,长度为 len
uint64 a;
pte_t *pte;
for(a = PGROUNDDOWN(va); a < PGROUNDDOWN(va + size); a += PGSIZE){
if((pte = walk(pt, a, 0)) == 0){
panic("mmap_writeback: walk");
}
if(PTE_FLAGS(*pte) == PTE_V)
panic("mmap_writeback: not leaf");
if(!(*pte & PTE_V)) continue; // 懒分配
if((*pte & PTE_D) && (vma->flags & MAP_SHARED)){
// 写回
begin_op();
ilock(vma->f->ip);
uint64 copied_len = a - va;
writei(vma->f->ip, 1, a, copied_len, PGSIZE);
iunlock(vma->f->ip);
end_op();
}
kfree((void*)PTE2PA(*pte));
*pte = 0;
}
return 0;
}
收尾
-
修改
exit将进程的已映射区域取消映射,就像调用了munmap一样。运行mmaptest;mmap_test应该通过,但可能不会通过fork_test。 -
修改
fork以确保子对象具有与父对象相同的映射区域。不要忘记增加VMA的struct file的引用计数。在子进程的页面错误处理程序中,可以分配新的物理页面,而不是与父级共享页面。后者会更酷,但需要更多的实施工作。
//exit()
...
if(p == initproc)
panic("init exiting");
for(int i = 0; i < VMA_LENGTH; i++){
if(p->vma[i].valid){
munmap(p->vma[i].addr, p->vma[i].size);
}
}
// Close all open files.
for(int fd = 0; fd < NOFILE; fd++){
if(p->ofile[fd]){
struct file *f = p->ofile[fd];
fileclose(f);
p->ofile[fd] = 0;
}
}
...
//fork()
...
for(i = 0; i < NOFILE; i++)
if(p->ofile[i])
np->ofile[i] = filedup(p->ofile[i]);
np->cwd = idup(p->cwd);
for(i = 0; i < VMA_LENGTH; i++) {
struct vma *v = &p->vma[i];
if(v->valid) {
np->vma[i] = *v;
filedup(v->f);
}
}
safestrcpy(np->name, p->name, sizeof(p->name));
pid = np->pid;
...

https://shorturl.fm/0SM0C