Intro to Assembly Language
ISA(Instruction Set Architectures)
- 常见的ISA

Complex/Recuded Instruction Set Computing
以前的趋势是通过不断添加指令来达到精细的操作
复杂指令集|Complex Instruction Set Computing(CISC)
-
难以学习和理解
-
对于编译器来说不需要太多的工作
-
需要复杂的硬件
但是后来,一个相反的理念开始占据主导地位
精简指令集|Reduced Instruction Set Computing(RISC)
-
简单且小巧的指令集让构建更快的硬件变得容易
-
让软件通过组合简单的操作来完成复杂的操作
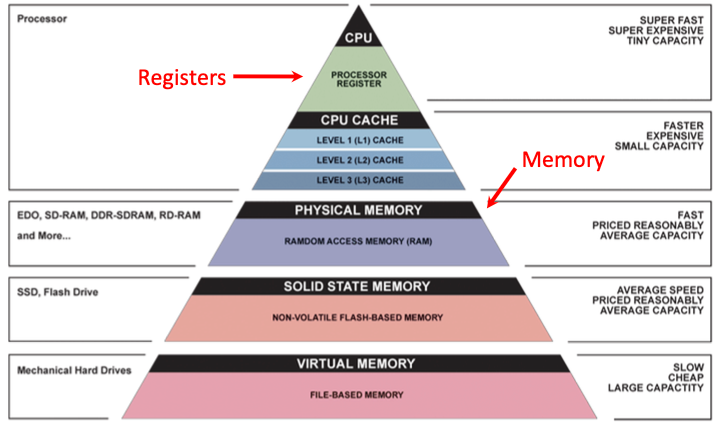
Register
-
汇编语言没有变量。它用寄存器(register)来存储值。
-
寄存器是固定大小的小内存 (取决于你的系统,我们使用32bit)。可以进行读取和写入(read and write),但是有数量限制,它们很快并且耗电少。
What if more variables than registers?
如果变量多于寄存器数量,我们选择将最常用的变量存储到寄存器中,然后将其余的存储到内存中。(称为 spilling to memory)
Why are not all variables in memory?
寄存器比内存快 100-500 倍。
Great Idea #3 : Principle of Locality/Memory Hierarchy
How Many Registers
RISCV有32个寄存器,每一个寄存器都是32位宽(32 bits wide),保存一个字
字是一个固定的大小,被指令集或者硬件作为一个单元(unit)来处理。通常字(word)被定义成寄存器的大小
a word is a fixed-sized piece of data handled as a unit by the instruction set or hardware of the processor. Normally a word is defined as the size of a CPU’s registers.
RISCV Registers

s 开头的寄存器称为 safe registers,它们用来保存程序变量。
t 开头的寄存器持有临时变量。
x0
0经常出现,所以x0是专门用于保存0的寄存器,它不能被更改
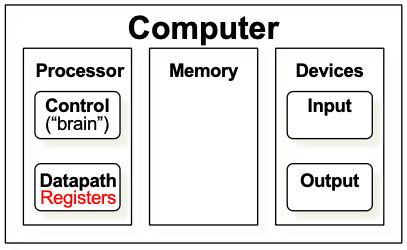
Registers in a Computer
Basic Instructions
RISCV Instructions
op dst, src1, src2
-
op= operation name (“operator”)
操作 -
dst= register getting result (“destination”)
存储结果的寄存器 -
src1= first register for operation (“source 1”)
操作的源寄存器1 -
src2= second register for operation (“source 2”)
操作的源寄存器2
这种规范的语法保持硬件的简洁
汇编指令必须和C语言中的一些操作密切相关,比如operations (=, +, -, *, /, &, |, etc)
因为C语言代码会被分解成汇编代码
Arithmetic Instructions
Integer Addition(add)
在 C 语言中:
a = b + c
在 RISCV 中:
add s1, s2, s3 # s1 = a
Integer Subtraction(sub)
在 C 语言中:
a = b - c;
在 RISCV 中:
sub s1, s2, s3 # s1 = a, s2 = b, s3 = c
RISCV Instructions Example
假设
a = s0, b = s1, c = s2, d = s3, e = s4。
将 a = (b + c) - (d + e) 转换为 RISCV语法。其中,t1 和 t2 是存储临时变量的寄存器。
add t1, s1, s2 # t1 = b + c
add t2, s3, s4 # t2 = d + e
sub s0, t1, t2 # s0 = t1 - t2 = (b + c) - (d + e)
Immediates
立即数(Immediates): Numerical constants
opi dst, src, imm
操作的名称结尾加个 ‘i’。
Immediates 可以达到 12 bits
addi s1, s2, 5 # a = b + 5
addi s3, s3, 1 # c 存储在 s3 中,相当于 c ++
假设 a -> s0, b -> s1, 将 a = (5 + b) - 3; 转换为 RISCV
addi t1, s1, 5 # t1 = 5 + b
addi s0, t1, -3 # a = t1 - 3
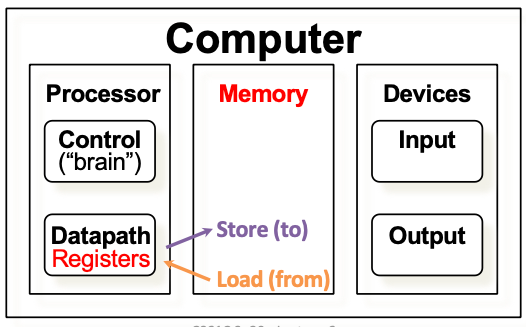
Data Transfer
C的变量被映射成寄存器,那么更大一些的数据结构怎么办呢?比如数组
- 汇编也可以访问内存!
但是RICSV只通过操作寄存器来实现!
一些专门用于在寄存器和内存中交换数据的指令:
-
Store: register TO memory
-
Load: register FROM memory
memop reg, off(bAddr)
-
memop:操作(名)
-
reg:目的或者源寄存器
-
off:即offset,偏移量
-
bAddr:即base address,基址
Memory is Byte-Addressed
不同系统下字是不一样大的
| 系统 | 字 | 字节 | 位 |
|---|---|---|---|
| 16 位 | 1 word | 2 Bytes | 16 bits |
| 32 位 | 1 word | 4 Bytes | 32 bits |
| 64 位 | 1 word | 8 Bytes | 64 bits |
内存地址(memory addresses)是由byte而不是word来索引
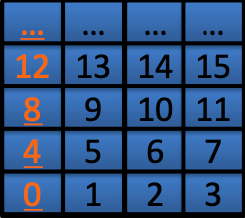
字地址(word addresses)以4byte来分割(32位系统下)

地址必须是4的倍数,这称之为字对齐(word-aligned)
Word addr vs Memory addr
- 粒度:内存地址是按字节索引的,而字地址是按字的边界索引的。这意味着内存地址有更细的粒度。
- 对齐:字地址隐含了对齐要求,而内存地址则没有这样的限制。
- 用途:在汇编语言中,指针或地址的使用必须考虑到你是在处理字节还是整个字。如果是字,你需要确保地址是字对齐的。
例如,假设你有一个32位系统,并且有一个整型变量(通常占用4字节)存储在内存地址0x1000:
- 内存地址可能是0x1000, 0x1001, 0x1002, 0x1003,每个地址代表变量中的一个字节。
- 字地址只关心起始地址,即0x1000,因为这是变量(一个字)的起始位置
Data Transfer Instructions
lw(Load Word)
- 从内存中地址为bAddr + off的位置取数据放进寄存器中
sw(Store Word)
- 从寄存器中获取数据存入内存中地址为bAddr + off的地方
Example
C:
array[10] = array[3] + b
RISC-V
lw t0, 12(s3) # t0 = A[3]
add t0, s2, t0 # t0 = A[3] + b
sw t0, 40(s3) # A[10] = A[3] + b
Values can start off in memory
.data 段是用来声明初始数据的。它用于存放程序中用到的静态数据,这些数据在程序开始执行前就已经存在,并且具有初始值。比如
.data
num: .word 123 # 声明一个名为num的整数,初始值为123
str: .asciiz "Hello, World!" # 声明一个以null结尾的字符串
.text 段是用来存放程序的可执行指令的。这是程序的主体部分,包含了所有的函数和程序逻辑。当程序运行时,CPU会从 .text 段读取指令并执行它们。

Endianness
大端法(big endian)和小端法(little endian)(源自格列佛游记,鸡蛋是打大头还是小头)

RISC-V使用小端法
Sign Extension
符号扩展(Sign Extension),它将一个较小的数据类型的符号位(通常是最左边的位,即最高位)扩展到更大的数据类型中。这个过程保持了数值的符号(正数或负数)不变。
符号扩展的目的:符号扩展是为了在将较小宽度的数据(例如8位)加载到较大宽度的寄存器(例如32位或64位)时,保持数据的符号。符号扩展会将寄存器中高于原始数据位宽度的所有位设置为原始数据最高位(符号位)的值。这样,如果原始字节是一个负数,那么在寄存器中的32位或64位表示也将是负数。
Sign Extend
用最高有效位(most-significant bit)填充

0b 11 = 0b 1111
举个例子
-2的4位二进制原码表示是1010,补码就是1110,扩展最高位到5位11110,这时候我们再求一下原码,10010,还是-2
Zero/One Pad
用0或1来填充
- Zero Pad:
0b 11 = 0b 0011
- One Pad:
0b 11 = 0b 1111
所有RISC-V指令都要需要的时候进行符号位扩展
除了auipc和lui,因为他俩就是用来填充高位的。
Byte Instructions

lb/sb只用寄存器最低位的一个字节
-
sb高位的24个bits将会被忽略 -
lb高位的24个bits将会用符号位扩展填充
lb指令读取的是内存中的一个8位字节。如果这个字节代表一个有符号整数(即它的最高位是符号位),那么在将其加载到更大的寄存器时,需要保持这个整数的符号。sb指令的目的在于将寄存器中的一个字节(8位)写入到内存中的一个字节大小的位置。这意味着只有寄存器中的最低8位会被写入,其他位不会影响存储操作。
E.g.
s0 = 0x00000180
lb sl, 1(s0) # s1 = 0x00000001
lb s2, 0(s0) # s2 = 0xFFFFFF80
sb s2, 2(s0) # *(s0) = 0x00800180
注意上面,lb和sb都是针对byte操作的,而一个hex位是4bits,也就是一次操作的是两个hex位。
Half-Word Instructions
“半字指令”,操作半个字,在32位系统下是两个byte,16个bit

-
sh"save half",高位的16bits将会被忽略 -
lh"load half",高位的16bits将会用符号位扩展填充
Unsigned Instructions
无符号操作

为什么没有s(h/b)u?为什么没有lwu呢?
-
对于存储指令(
sb,sh,sw),它们是将寄存器中的数据直接写入内存,而不关心数据是有符号还是无符号。因此,存储指令不需要区分有符号和无符号,因为它们只是简单地复制寄存器中的位到内存中。 -
因为已经有
lw存在,lw直接将32bit位的东西存进寄存器,而寄存器已经是32位的了,没有空隙来进行符号位扩展了。
Data Transfer GreenCard Explanation

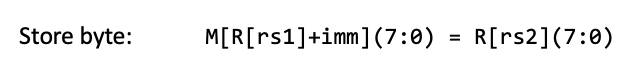
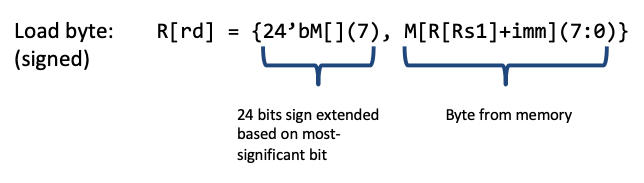
这个意思就是低8位是从内存中取出的地址,高24位是利用符号位扩展得到的。
Control Flow Instructions
Decision Making Instructions
beq(Branch If Equal)
如果reg1里面的值和reg2里面的值相等,就跳转到lable处,如果不,就执行下一个命令
beq reg1, reg2, lable
bne(Branch If Not Equal)
如果reg1里面的值和reg2里面的值不相等,就跳转到lable处
bne reg1, reg2, lable
j(Jump)
无条件跳转
j lable

Branch on Conditions other than (Not) Equal
blt(Branch Less Than)
如果reg1里面的值小于reg2里面的值,就跳转到Label处
blt reg1, reg2, lable
bge(Branch Greater Than)
如果reg1里面的值大于等于reg2里面的值,就跳转到Label处
bge reg1, reg2, lable
关于为什么没有ble和bgt
RISC的哲学:
Why create a “branch greater than” if you could swap the arguments and use “branch less than”?
我们已经有了一条只需要交换参数就可以完成任务的命令,为啥要多创建一条命令呢?
Loops in RISCV
在RISCV中,有很多种方式可以创建一个循环。关键在于条件转移指令,因为没有这个的话循环将会一直执行。
Program Counter(PC)
条件转移和跳转指令改变代码执行顺序的本质就是通过修改Program Counter
PC是什么?
PC是一种特殊的寄存器,它存储着将要被执行的代码的地址,且它作为一个特殊的寄存器是不可以像正常的32位寄存器一样被访问的。
Instruction Addresses
指令作为数据存储在 memory 中并且有自己的地址。
Labels 会被转换为指令的地址。
PC 会跟踪 CPU 当前执行的指令。
Control Flow Greencard Explanation

imm 的第 0 位是 1,来保证它是偶数,这样 PC 的值总是会半对齐。因为我们需要支持半字指令
在 RISC-V 中,分支立即数是一个12位的值,但只有高11位是可变的,最低位(第0位)被硬编码为1。这个12位的立即数在计算跳转目标地址时会被解释为一个有符号的偏移量,并且这个偏移量会被左移1位(乘以2)。
举个例子:
-
假设立即数的高11位是
imm[11:1] = 0b0000_0000_0010(即2的二进制表示),硬编码的最低位是1,所以立即数是0b0000_0000_0011(即3的二进制表示)。 -
当这个立即数左移1位时,结果是
0b0000_0000_0110(即6的二进制表示),这是一个偶数。
Shifting Instructions
二进制里面shifting left一个无符号数就相当于将这个数乘2
-
但是位移操作要快得多
-
shifting right不能当作除2
位移操作的种类
-
逻辑位移:当进行位移操作的时候补0
-
算数位移:进行位移操作的时候采用符号位扩展(只在右移的时候有效,且会保留符号)
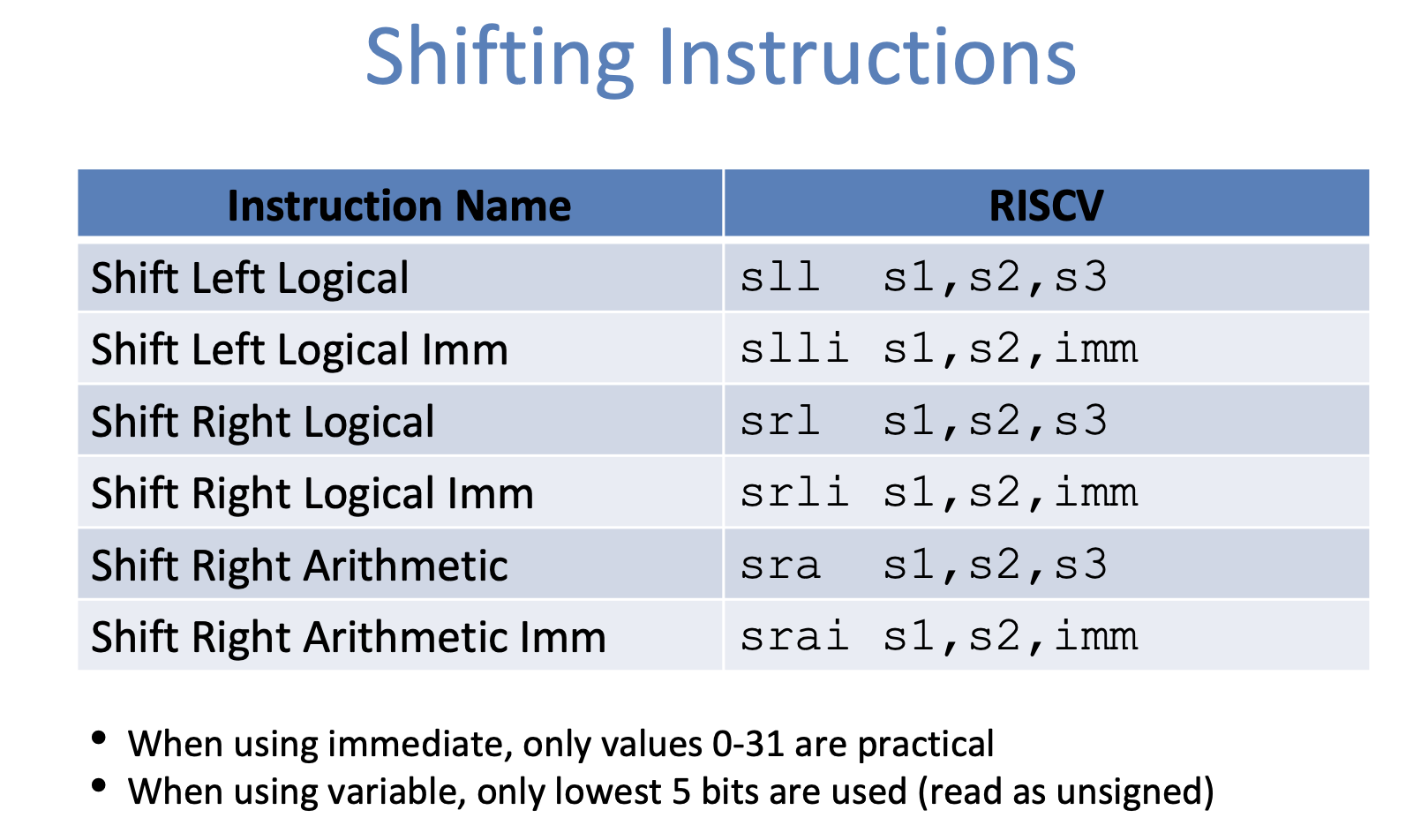
- 一些例子
空格以后的例子展现了如何利用第五位的数据。

- 如果机器不支持lbu,但是支持lw
通过先取整个字,在与bit掩码进行逻辑运算实现取单个字节的方法

- 如果机器不支持sb,但是支持sw
一样的原理

假设 s0: 0x12345678。s1: 0xAB
lw t0, 0(s0) 从 s0 地址读取当前值 0x12345678 到寄存器 t0,t0 = ‘0x12345678’。
li t1, 0x00FFFFFF 将立即数 0x00FFFFFF 加载到寄存器 t1。t1 = 0x00FFFFFF。
and t0, t0, t1 将 t0 与 t1 按位与,清除 t0 的最高字节。t0 = ‘0x12345678’ & ‘0x00FFFFFF’,最终 t0 = ‘0x00345678’(最高字节已经清零)
slli t1, s1, 24 将 s1 的值左移 24 位,将其移动到最高字节位置,也就是 0xAB <<24 -> t1 = 0xAB000000
or t0, t0, t1 将 t0 和 t1 按位或操作,合并新的最高字节。t0 = 0x00345678 | 0xAB000000,t0 = ‘0xAB345678’
sw t0, 0(s0) 将 t0 的值 0xAB345678 存储回 s0 地址,s0 = 0xAB345678
Other Useful Instructions
Arithmetic Instructions Myltiply Extension
Multiplication (mul and mulh)
因为两个32位的东西相乘,得到的最大结果就会是64位,所以我们用mul来指定低32位,而mulh指定高32位
mul dst, src1, src2
mulh dst, src1, src2
Division(div)
商通过div来取,余数通过rem来取
div dst, src1, src2
rem dst, src1, src2
Bitwise Instructions

Compare Instructions
slt(Set Less Than)
reg1小于reg2置0,否则置1
slt dst, reg1, reg2
slti(Set Less Than Immediate)
reg1小于imm置0,否则置1
slti dst, reg1, imm
