Muxes
Data Multiplexor
多路转换器是一个选择器,N-to-1
下面是一个n位的2选1多路选择器
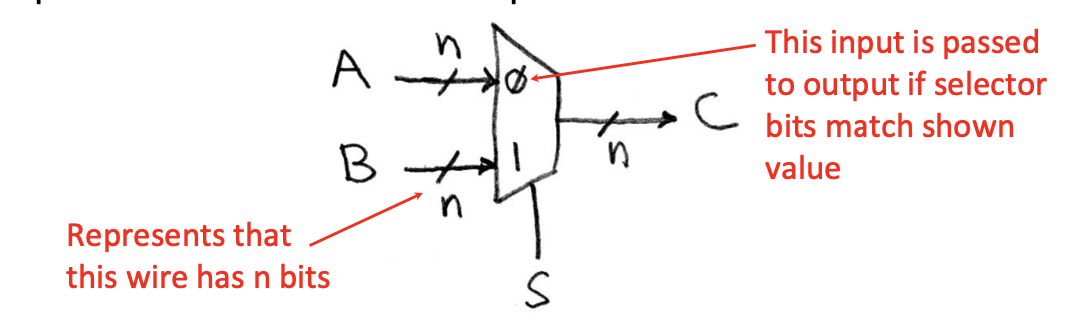
如图所示,接受了两个n位的输入,输出一个n位
接下来我们将来实现一个1位的2选一MUX
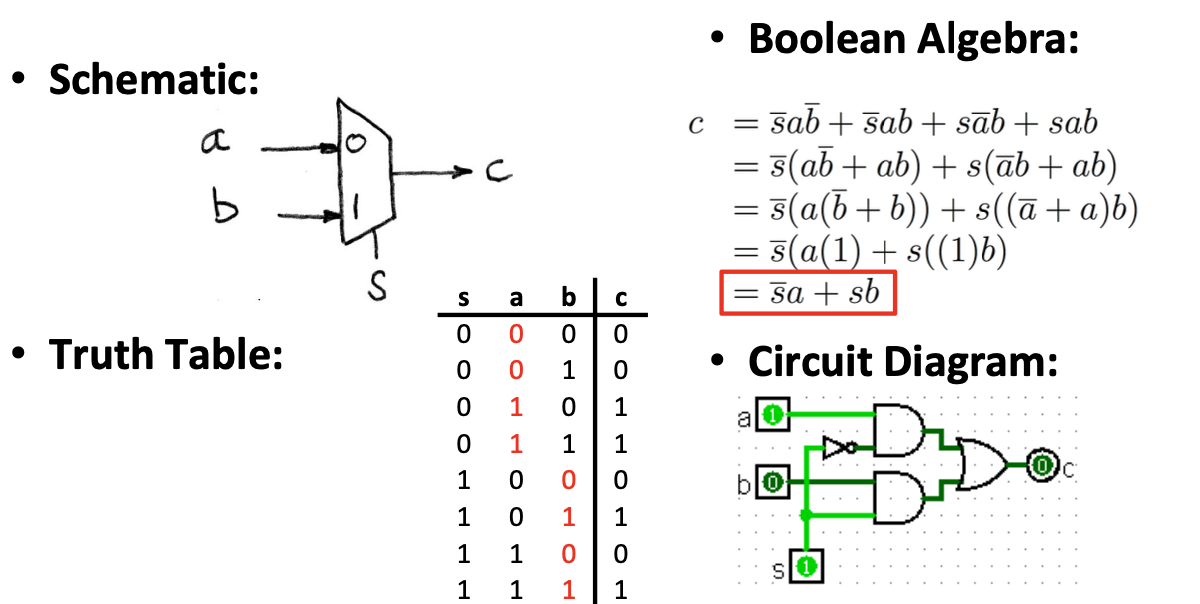
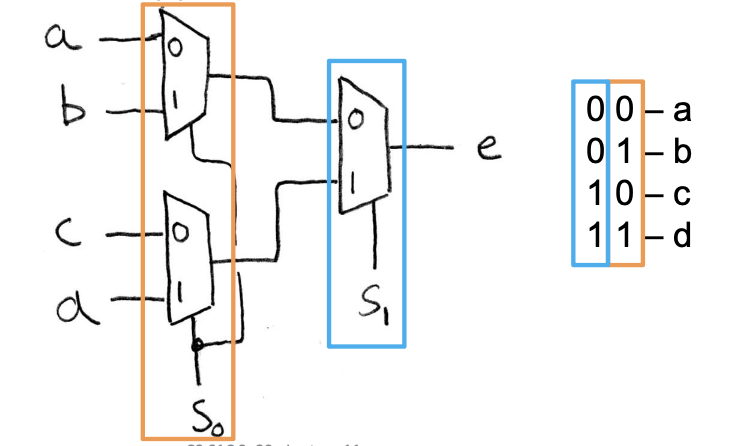
下面是一个1位4选一MUX的示例
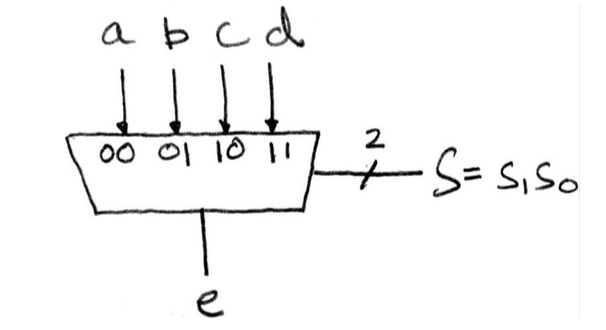
思考一下真值表会有多少行?
答案是
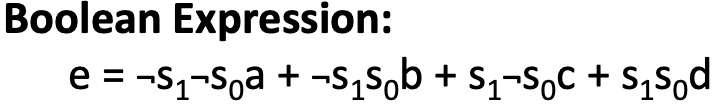
我们可以利用之前的2选1MUX来实现4选1MUX
State Circuits(Sequential Logic)
Uses for State Elements
可以用于寄存器或是内存。且可以用于控制组合逻辑电路之间的信息流,在组合逻辑模块之间,状态元素用于控制信息流动。它们可以在组合逻辑块的输入处暂停信息的移动,使得信息可以有序地传递。这意味着组合逻辑可以根据需要接收和处理数据,而不是立即处理所有输入。
Accumulator Example
接下来,我们将探寻一个累加器是如何实现的。
首先,累加器的概念如下
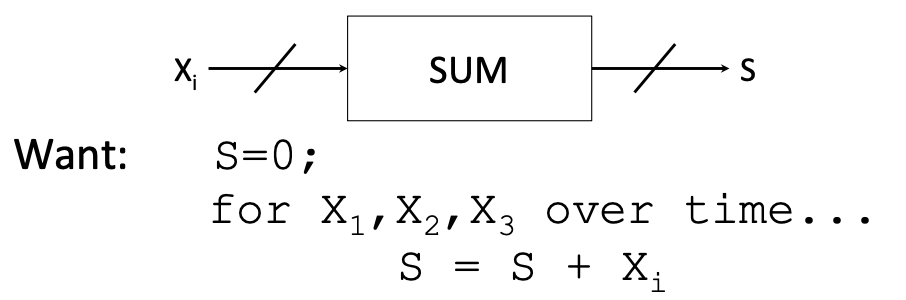
第一次尝试
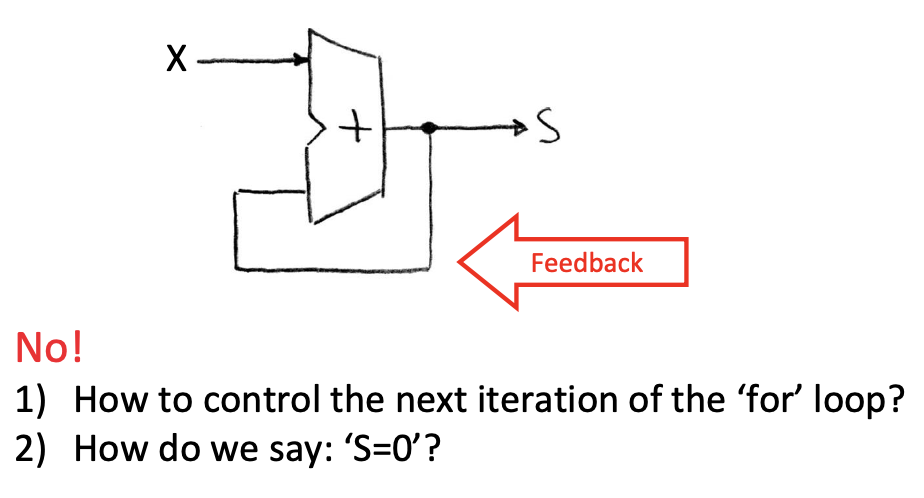
这样是行不通的
第一,我们无法控制循环的迭代()
第二,我们无法让s重置为0
所以我们采用一个寄存器来控制信息流,如下图所示
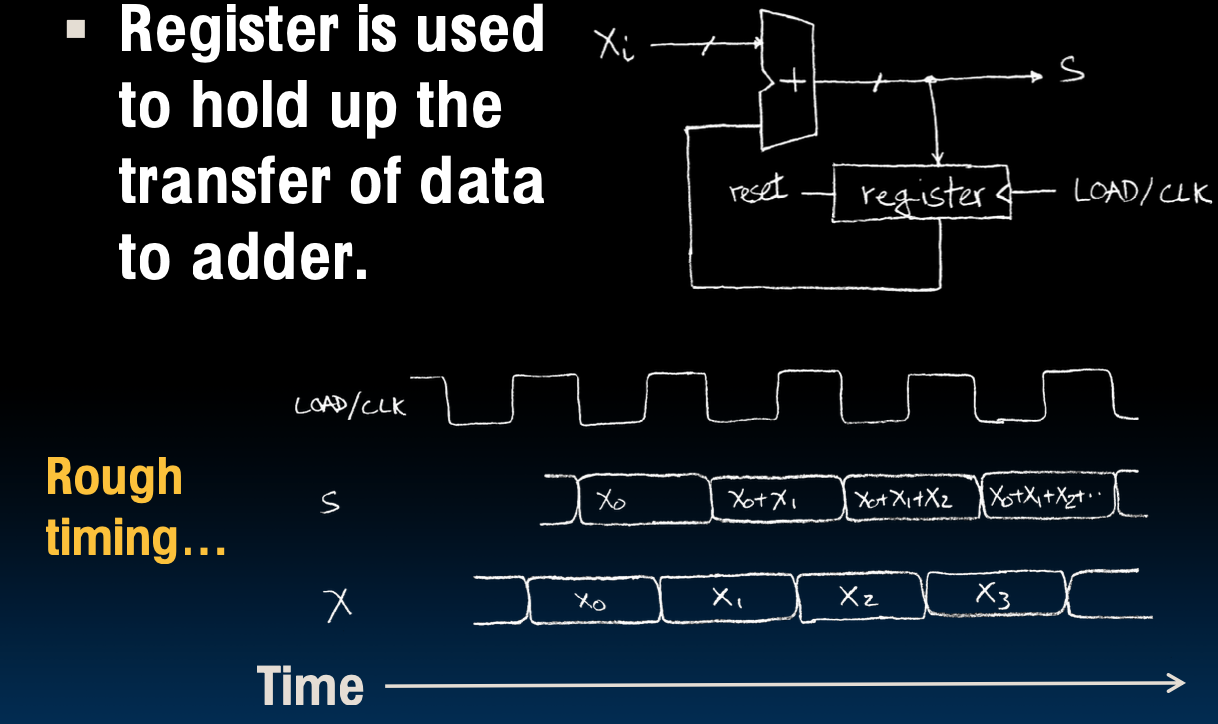
寄存器组织了向下的信息流,直到我们让它过,它才能过。那么我们如何决定是否放行信息流呢?
利用时钟(clock,就是经常在cpu上听到的那个clock)来控制。
Register Details

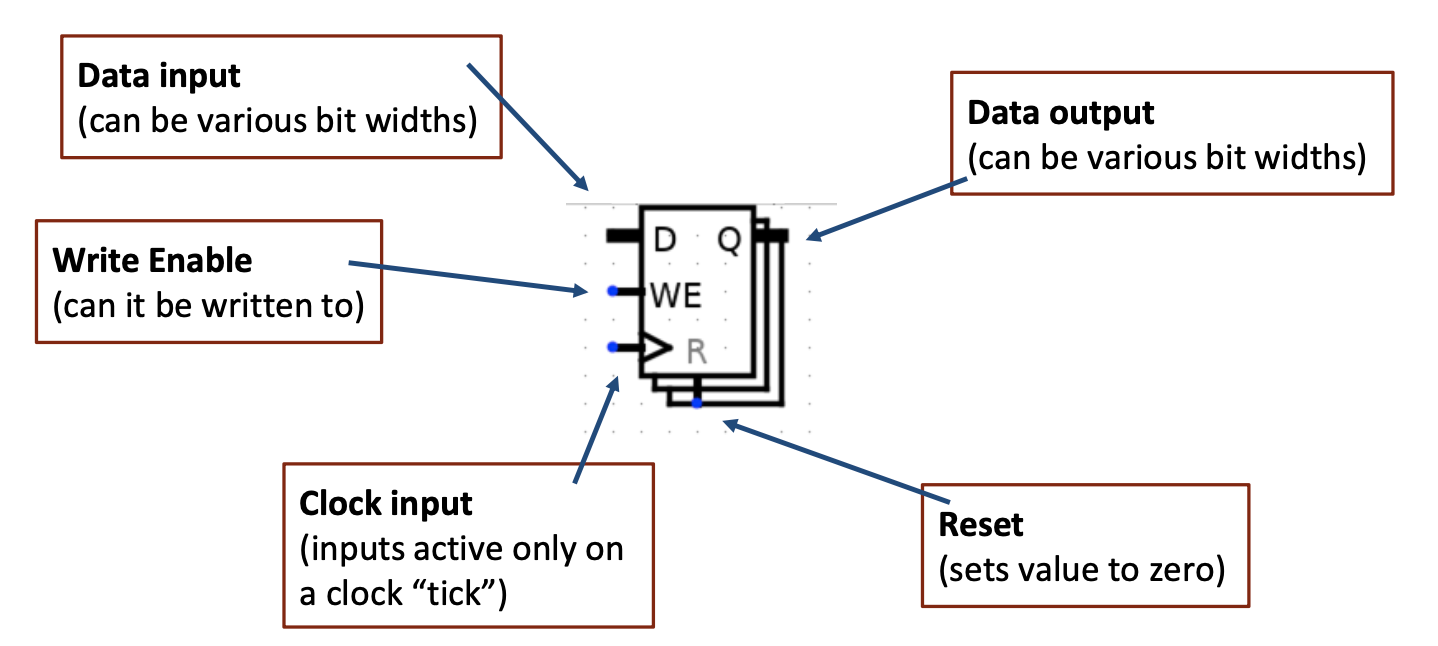
一个n位寄存器实际上是n个1位触发器
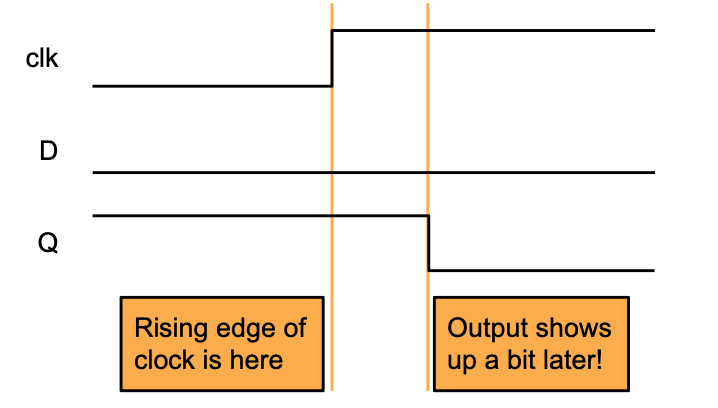
What's the timing of a Filp-flop
在时钟的上升沿,输入d被采样并传输到输出。在其他任何时候,输入d都会被忽略。
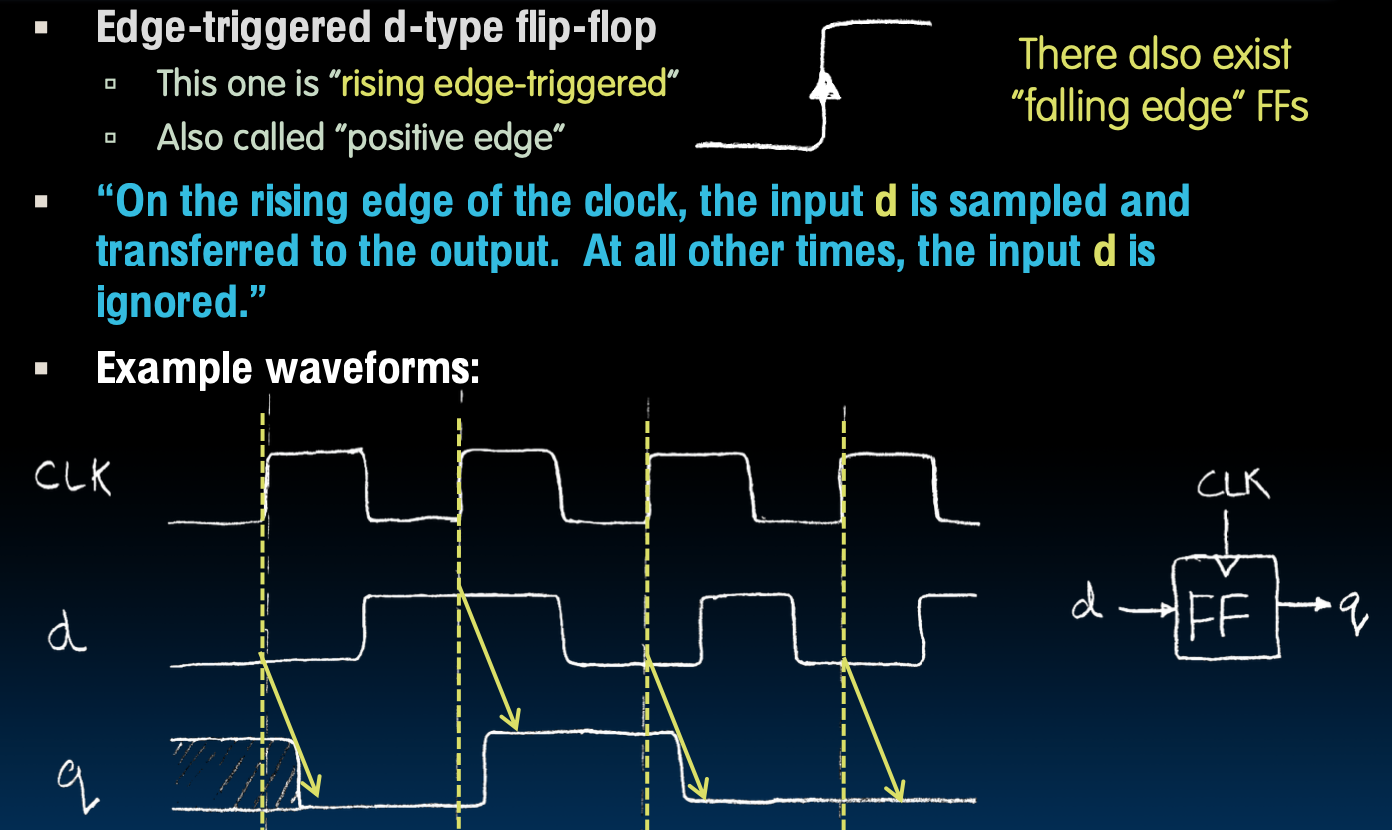

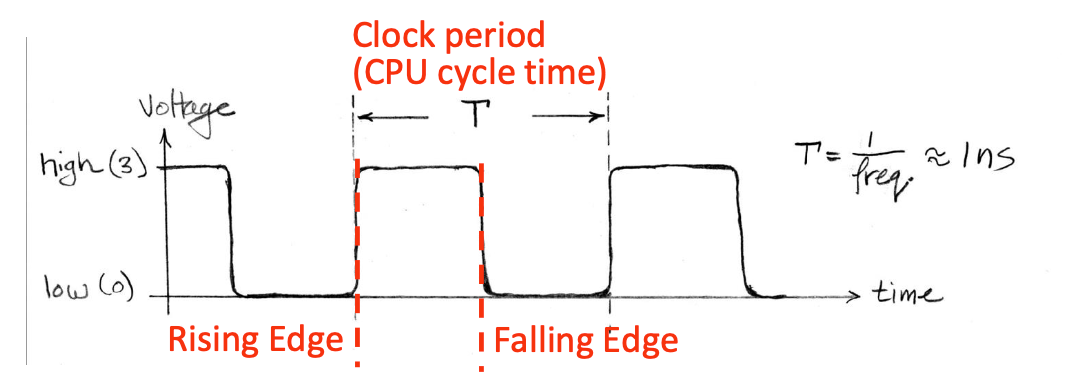
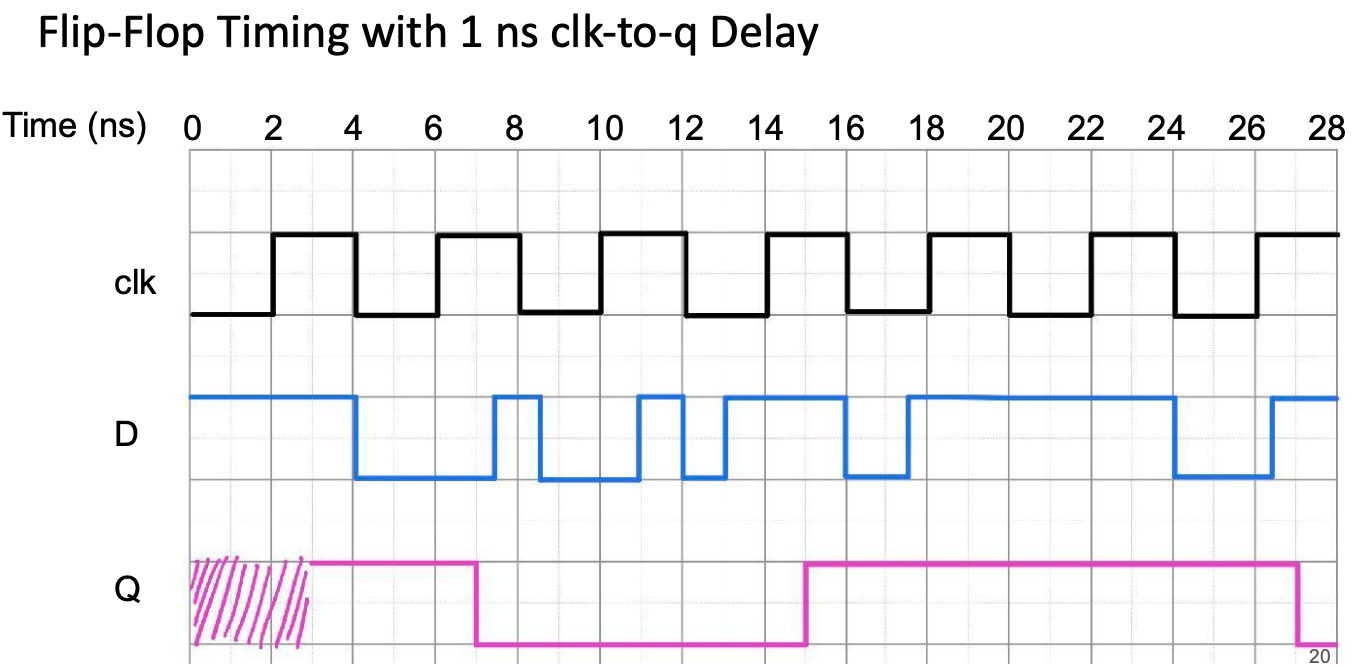
Signals and Wavefroms:Clocks
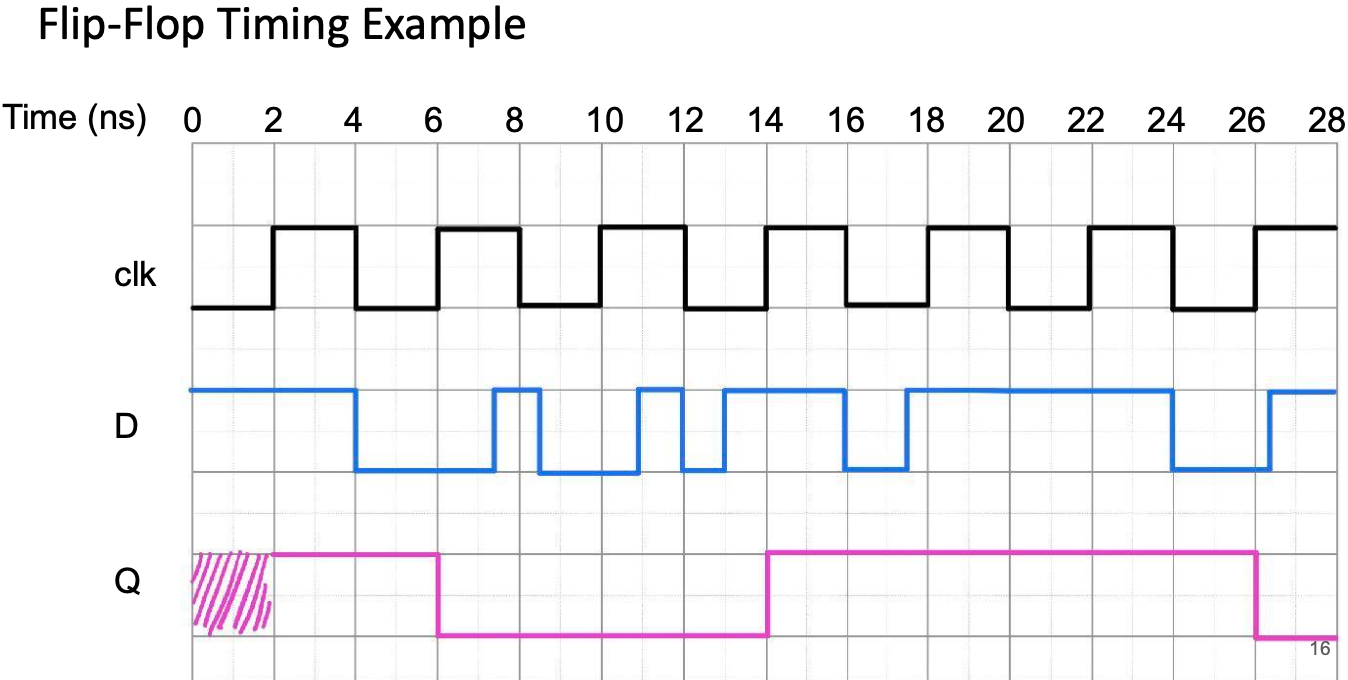
Register/Filp Flop Delay: clk-to-q delay
-
寄存器/触发器不能立即将 D 输入传输到 Q 输出。
-
从上升沿开始到Q输出变化所需的时间,即clk到q的延迟时间。
Combinational Delay
晶体管具有电阻和电容特性,这会影响它们切换的速度。当晶体管打开或关闭时,它们不会瞬间改变状态,而是需要一定的时间来转换。
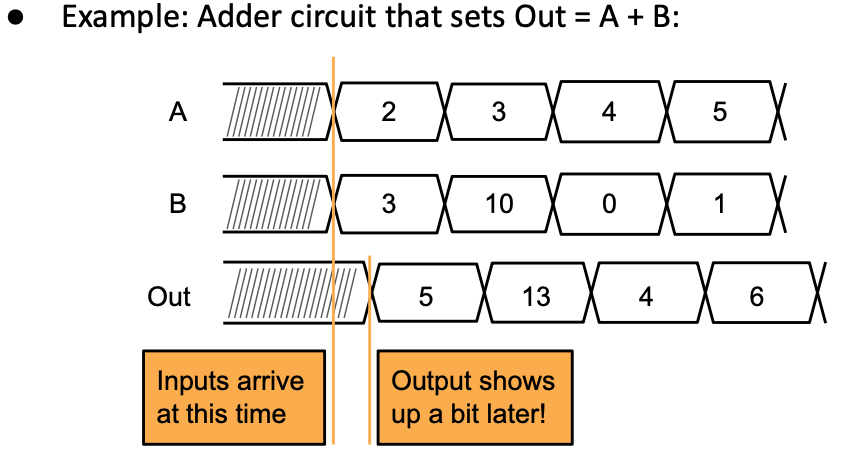
下面的例子给到了一个很好的练习,但是同时又引入了一个新问题
Maximizing Clock Frequency
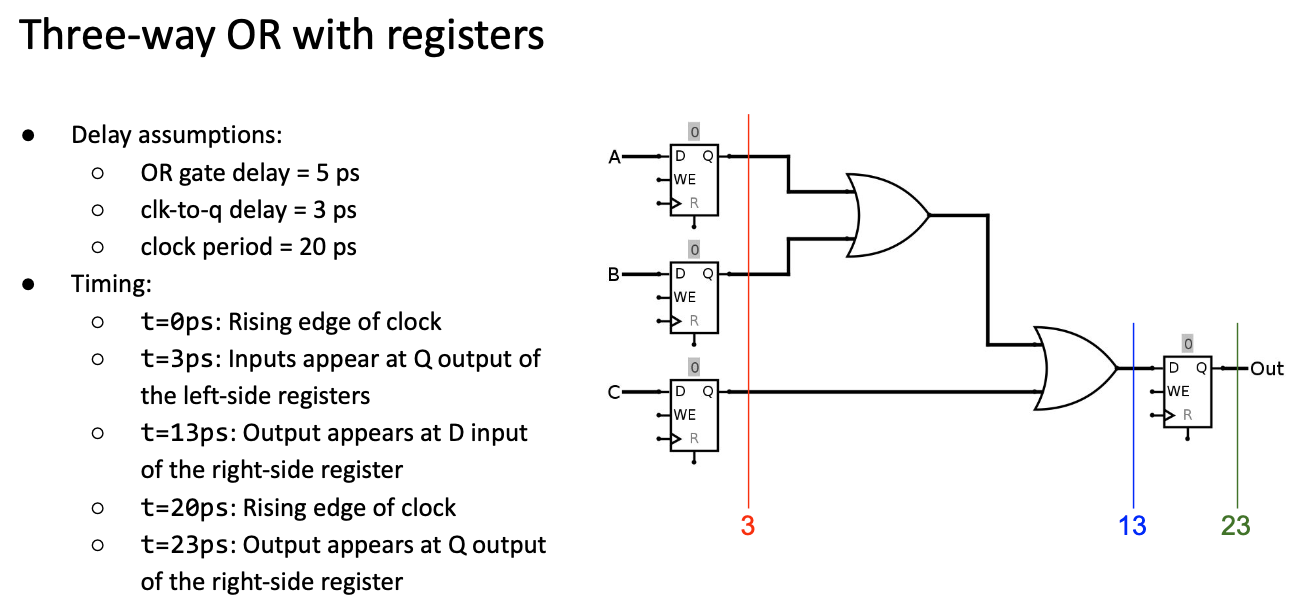
问题:
计算在t=13ps的时候就完成了,但是下一个上升沿在t=20ps的时候才会到。
解决办法:
降低时钟周期,这样我们就有更高的频率,也就会在每秒获得更多的计算次数,但是这样又会出现一个新问题
我们可以一直增加时钟频率吗?
当我们将时钟周期降低到10ps的时候我们会发现一件事情,第二个上升沿在t=10ps的时候就来了,但是此时我们还未到达寄存器,所以就得等到下一个上升沿t=20ps的时候了。
所以我们设想,可不可以将最大的时钟频率设置到Clk-to-q + critical path delay呢?在本个例子中,设置为13ps可不可以呢?这就引入了下面要介绍的几个概念。
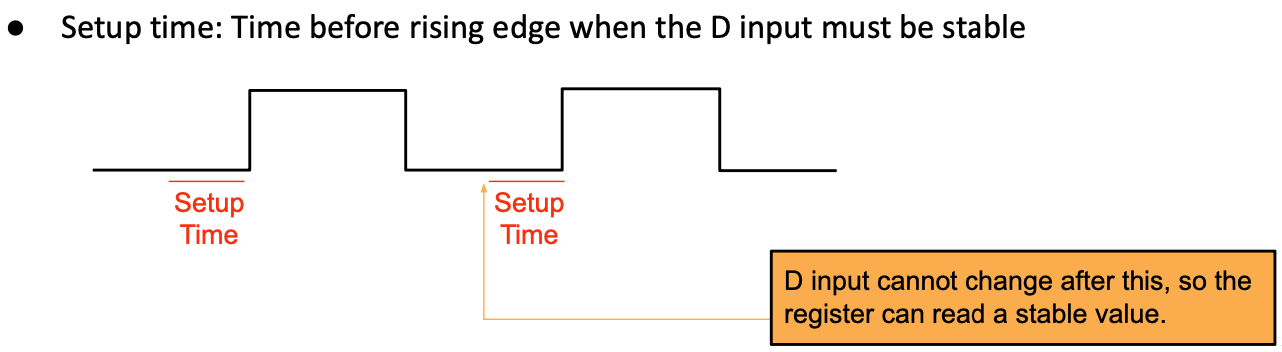
Register Constraints: Setup Time
假设时钟周期为20ps,如果信号在19.9ps时到达D输入端会发生什么?
在上升沿(t=20ps)时,D 输入还未稳定。 寄存器不知道该发送什么到 Q 输出!
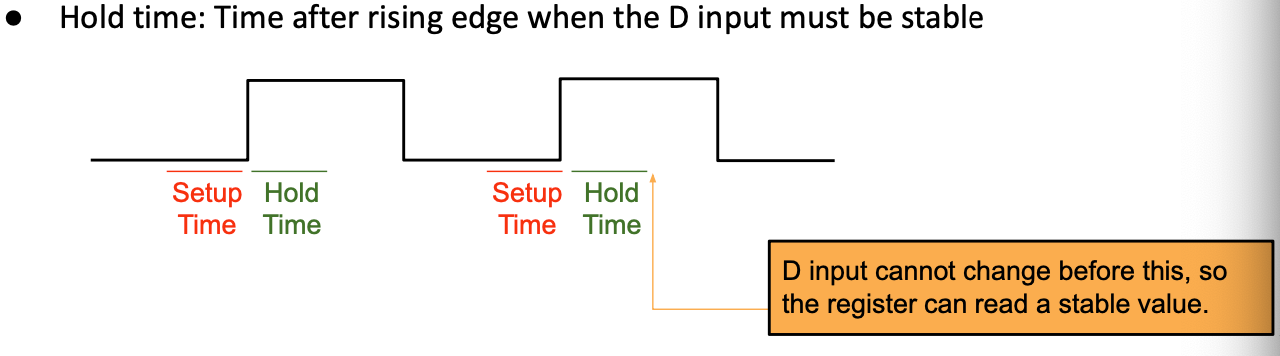
Register Constraints: Hold Time
假设时钟周期为20ps,如果新信号在20.1ps时到达D输入端会发生什么?
在上升沿(t=20ps)之后,D 输入还未稳定。 寄存器不知道该发送什么到 Q 输出!
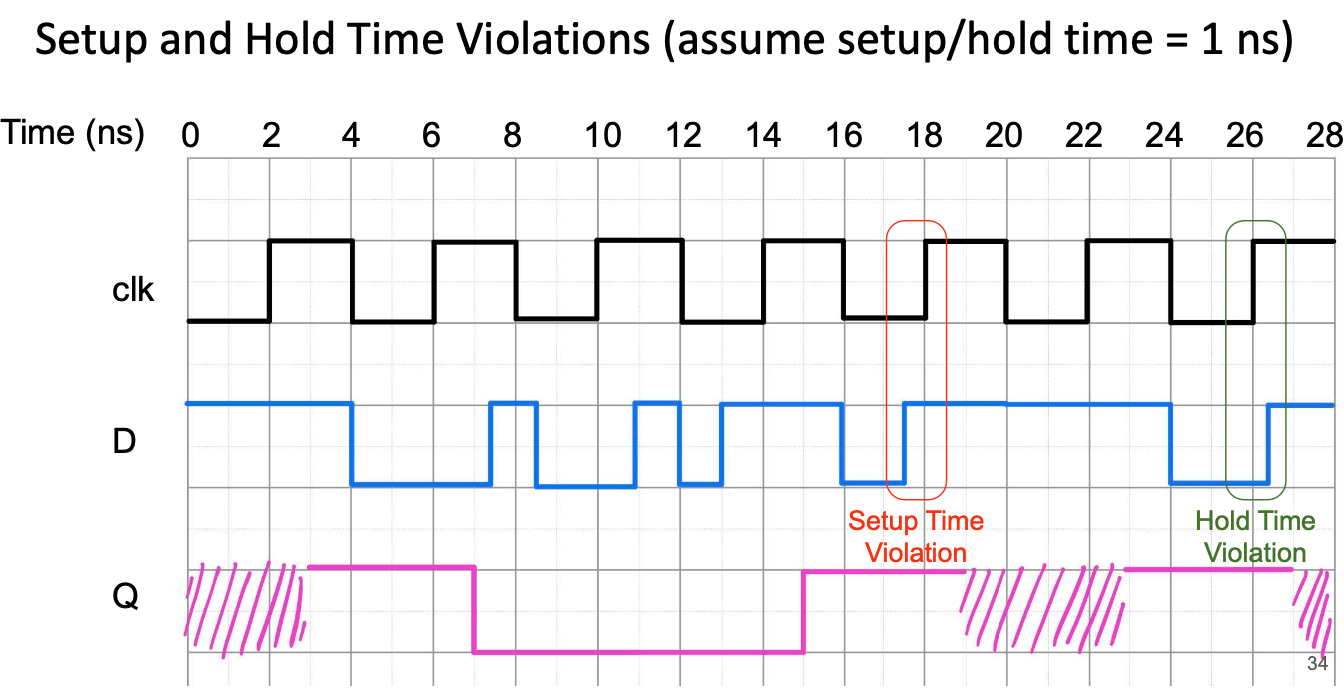
了解了上面两个新概念之后,我们便可以计算出最大的时钟频率
Clock period ≥ clk-to-q delay + longest combinational delay + setup time
在时钟上升沿之后,我们等待 clk-to-q delay 等待 Q 输出发生变化,然后等待最长组合逻辑延迟,最后确保数据在时钟边沿之前稳定。
此外我们还需要满足合适的Hold Time
Hold time ≤ clk-to-q delay + shortest combinational delay
在时钟上升沿之后,我们等待 clk-to-q delay 等待 Q 输出发生变化,然后在最短组合逻辑延迟之后,其中一个 D 输入会发生变化。我们需要确保保持时间超过这个点,以防止数据在时钟边沿之后发生改变。
Accumulator Revisited
了解了以上知识之后,再让我们来重新审视累加器
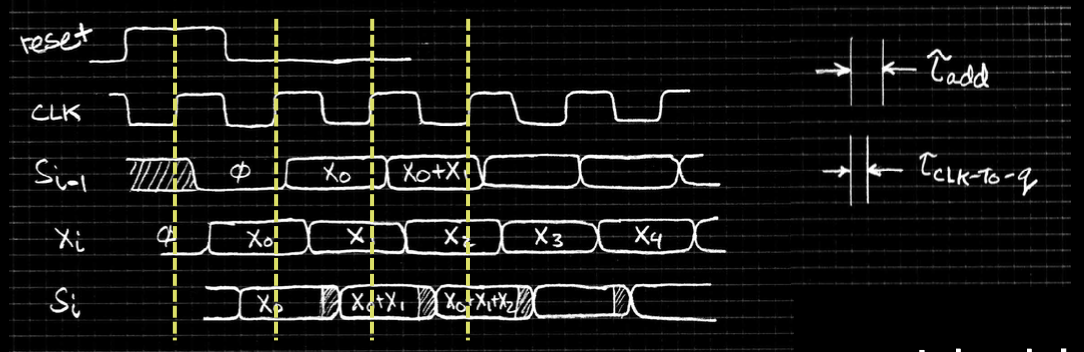
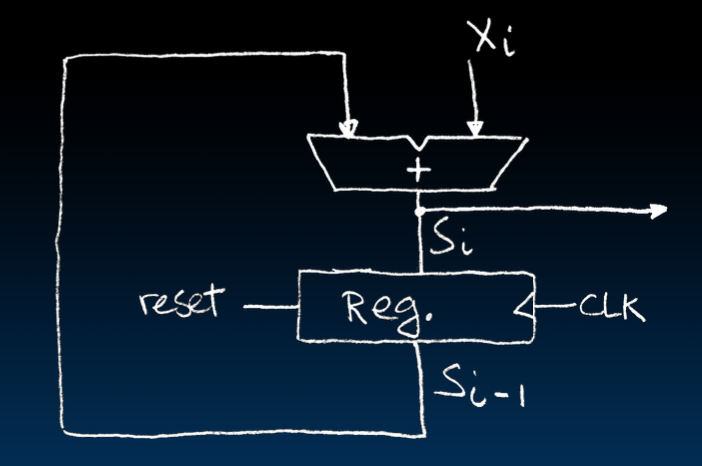
-
Reset的优先级比D输入要高
-
保存的是第i-1次迭代的结果 -
寄存器会短暂出现问题,但总是会得到正确数值。因为寄存器不会保存在Hold Time内变化的值。
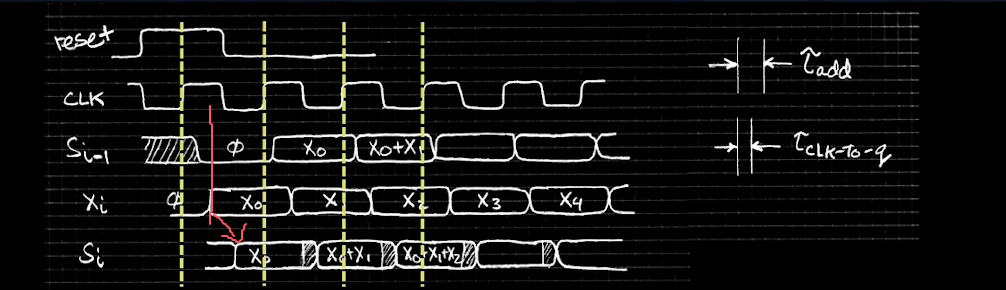
为什么Xi刚被设置成x0,CLK还没到一个上升峰值,Si就被设置成x0了
因为Si并不受CLK控制,受控制的是register
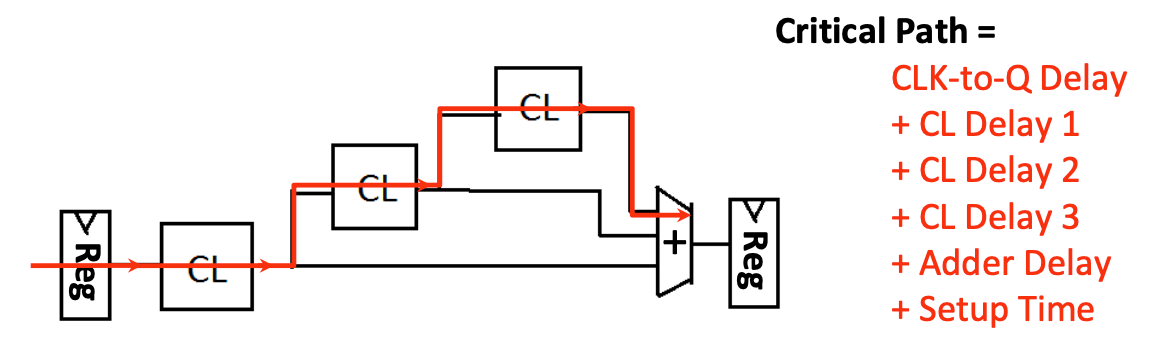
The Critical Path
关键路径是两个寄存器中拥有最大延迟的路径
时钟周期必须长于这个关键路径,否则信号将无法正确传播到接下来的寄存器。
Pipelining and Clock Frequency
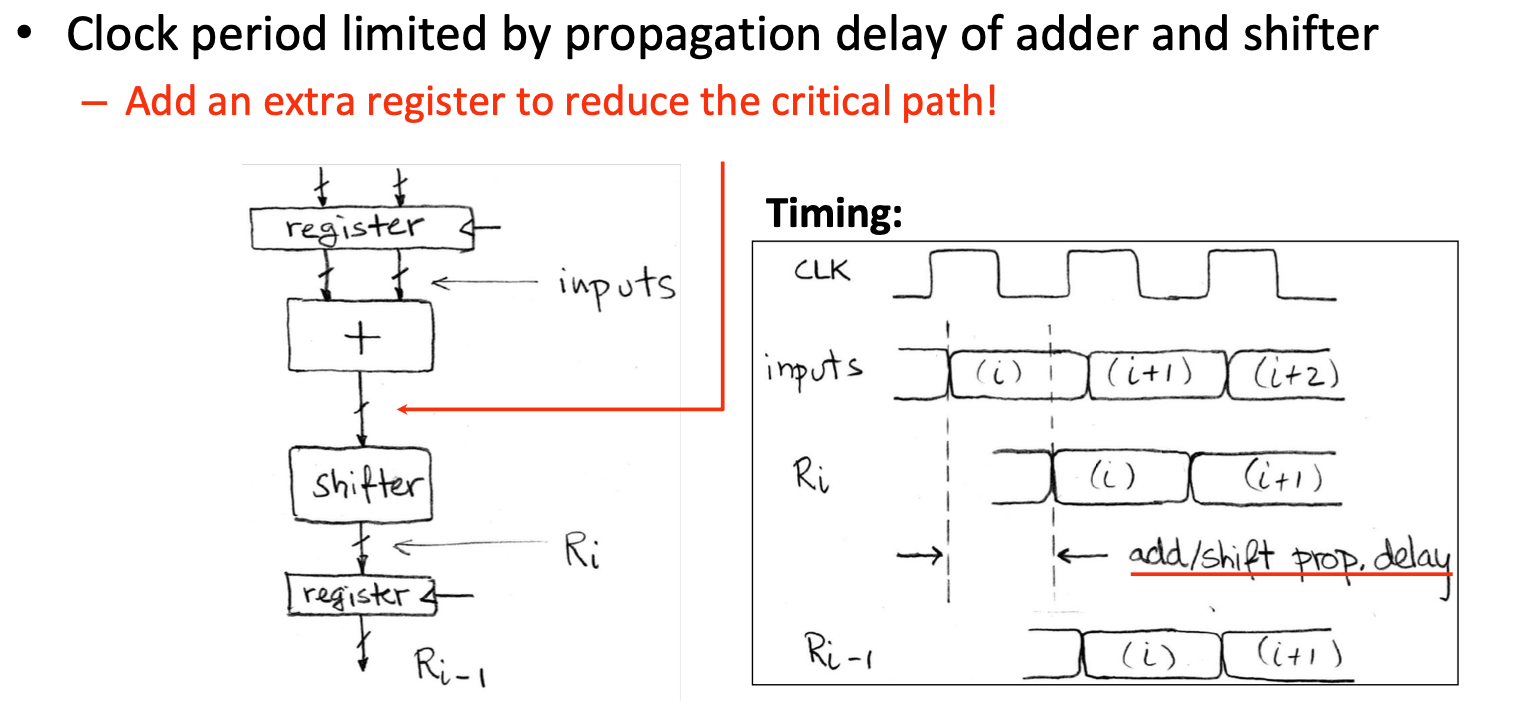
增加一个寄存器以此来减少关键路径
本来我们需要等待加法器和位移器,现在我们只需要等待一个加法器或者位移器了

减少关键路径->就允许有更高的处理器频率
额外的寄存器->拥有额外(缩短)的周期去"产出"(produce)第一个输出
类比
想象用桶灭火
• 一个人可以从池塘端着桶一路往火场走
或者
• 一排人可以把桶一直传到房子那里
人越多,拿到第一个桶的时间就越长。但以后的桶会快得多。
Pipelining Basics
-
通过增加寄存器来将路径划分成更小的部分
-
目的是缩短关键路径
-
信号将通过额外的时钟周期在每个部分传播
-
-
但是必须权衡利弊(寄存器不能到处乱放的原因)
- 更快的时钟频率带来了更高的吞吐量,但是也会造成更高的延迟(setup time,hold time,Clk-to-q delay)
总的而言,流水线是用于提高cpu性能的,但是并不是用的寄存器越多就越快。
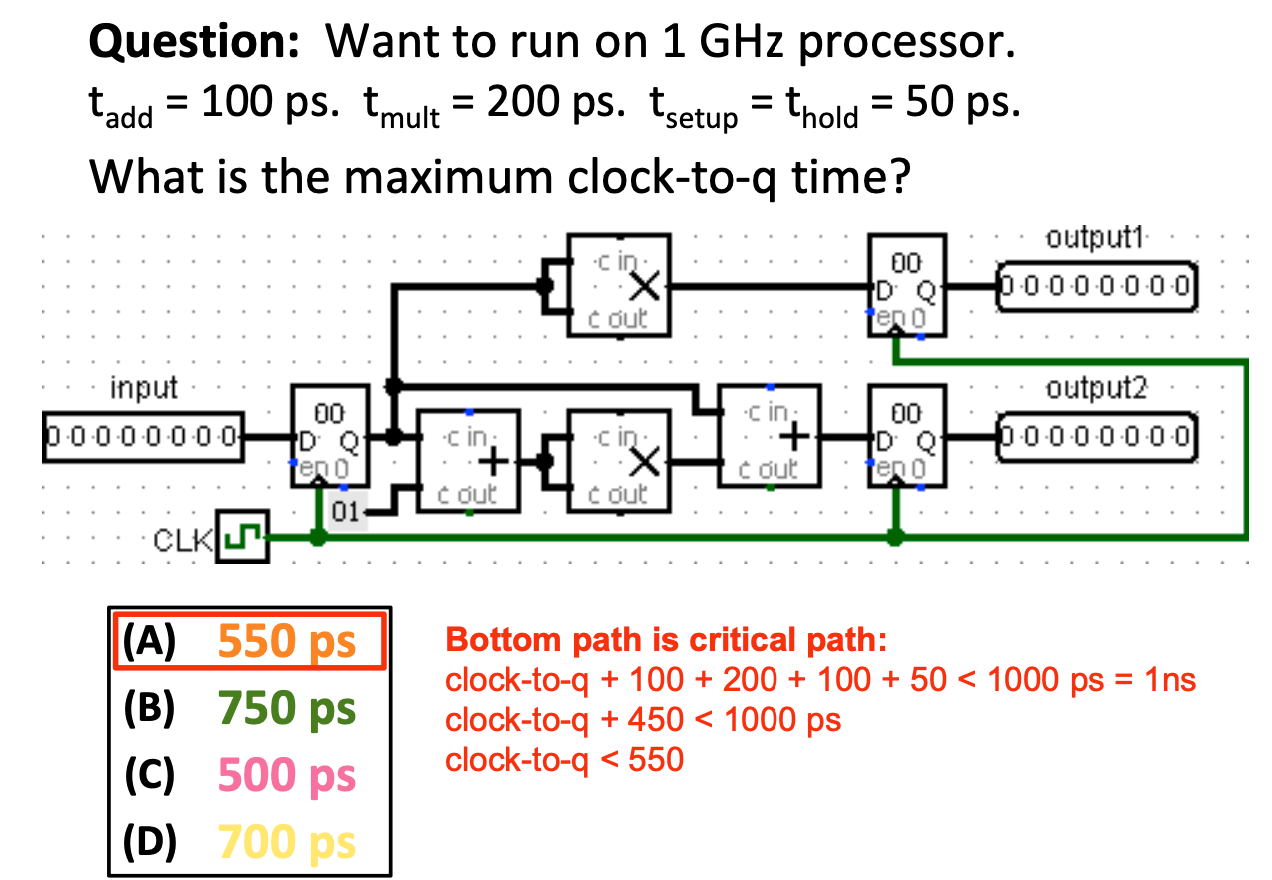
为什么在这里没有考虑Hold Time违规的情况??
首先,我们需要明确,Hold TimeViolation出现在寄存器已经拿到值之后,所以我们就得观察寄存器拿到值之后值会在什么时候发生变化
首先看上面右边的寄存器,我们需要过一个寄存器,再过一个乘法器,这个时间肯定超过了50ps,所以没问题
再看下面右边的寄存器,这时候我们不应该看关键路径的变化,因为关键路径的延迟是最长的,所以我们走的是中间的那条路,由输入经过一个寄存器和一个加法器最终达到下面右边的寄存器,很显然这个时间也大于50ps,所以不会出现Hold Time违规。
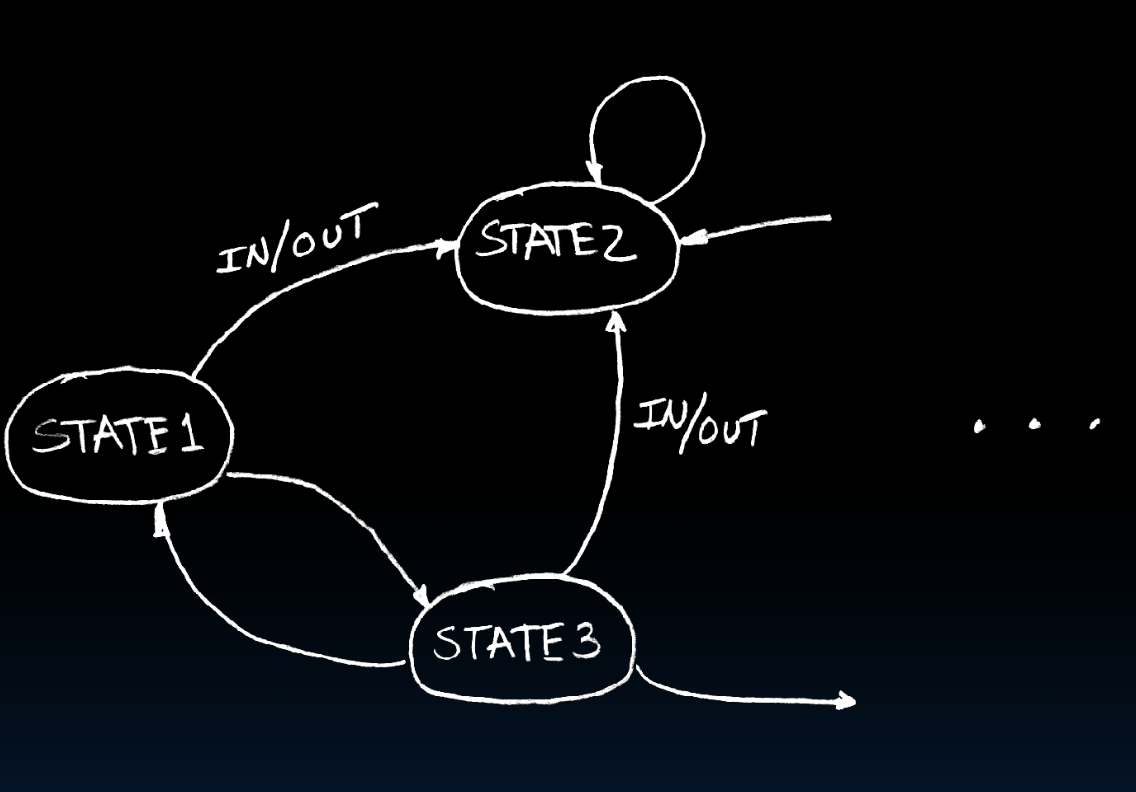
Finite State Machines
状态转移图如下
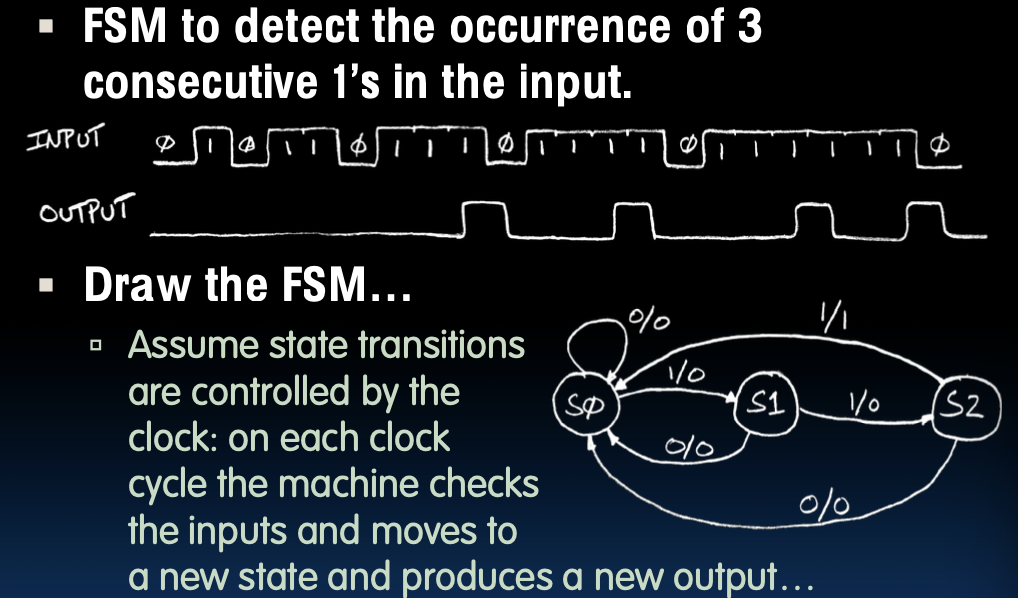
Example
1/0表示输入1,输出0;1/1表示输入1,输出1
Hardware Implementation of FSM
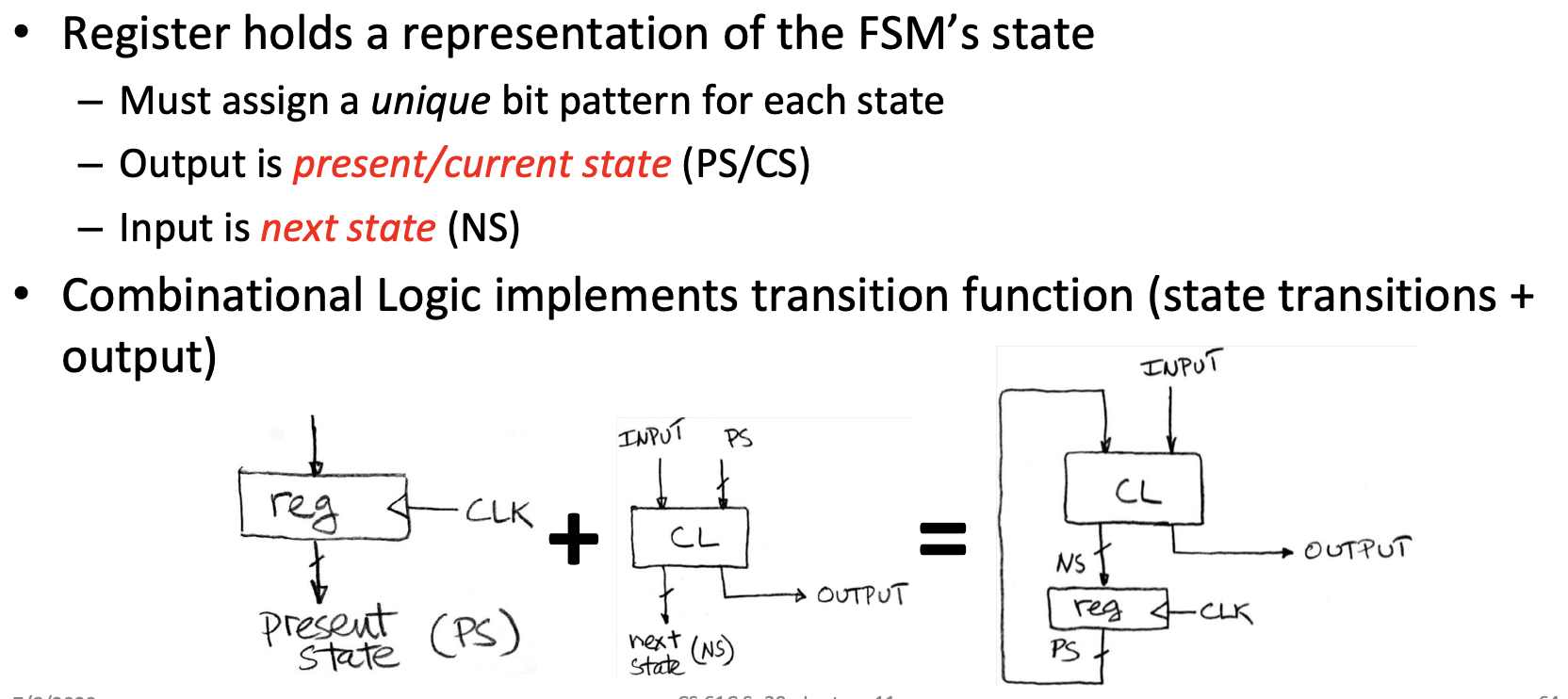
FSM:Combinational Logic
先根据状态转移图画出真值表
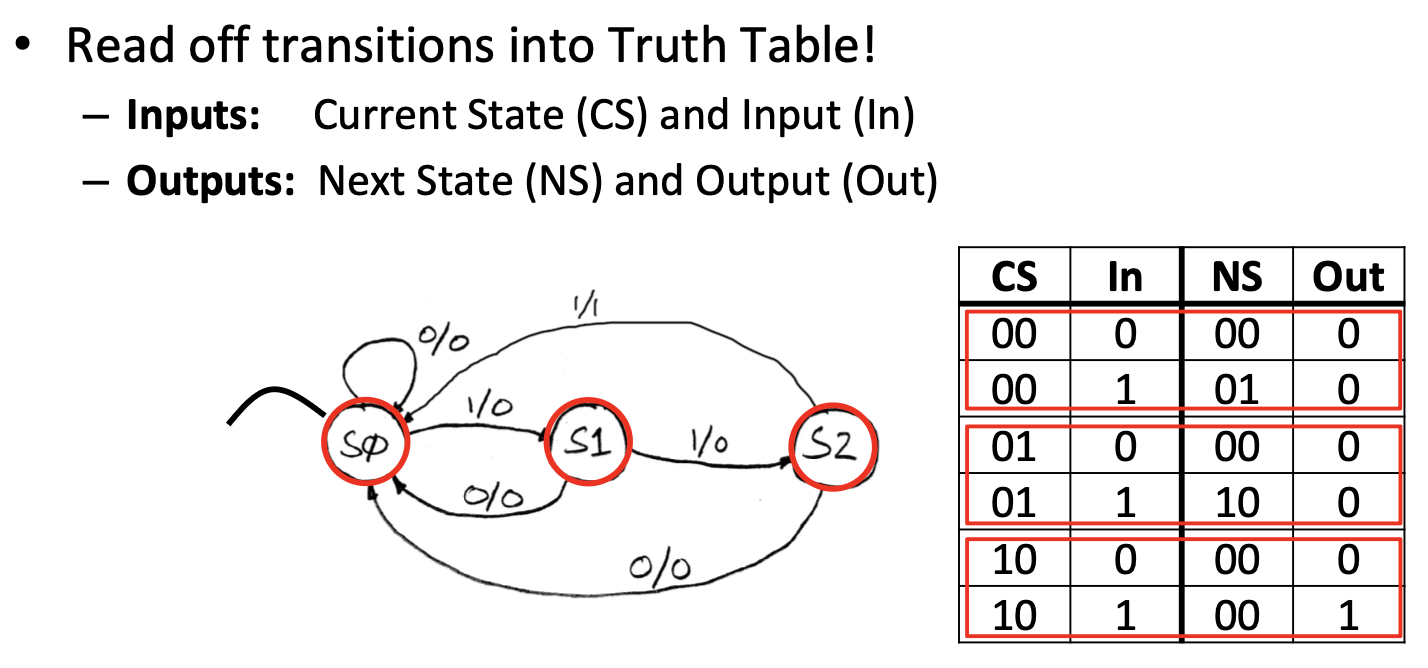
因为这个有限状态机只有三种状态,我们想要三种状态就需要2位的二进制来表示,但是这样会多出一个数,也就是
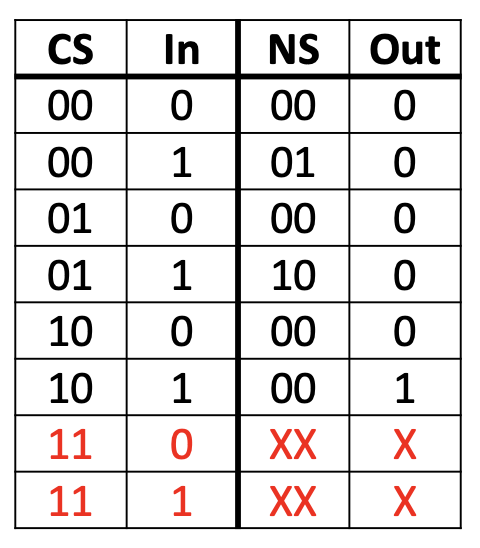
接下来,我们就可以根据真值表来列出布尔表达式
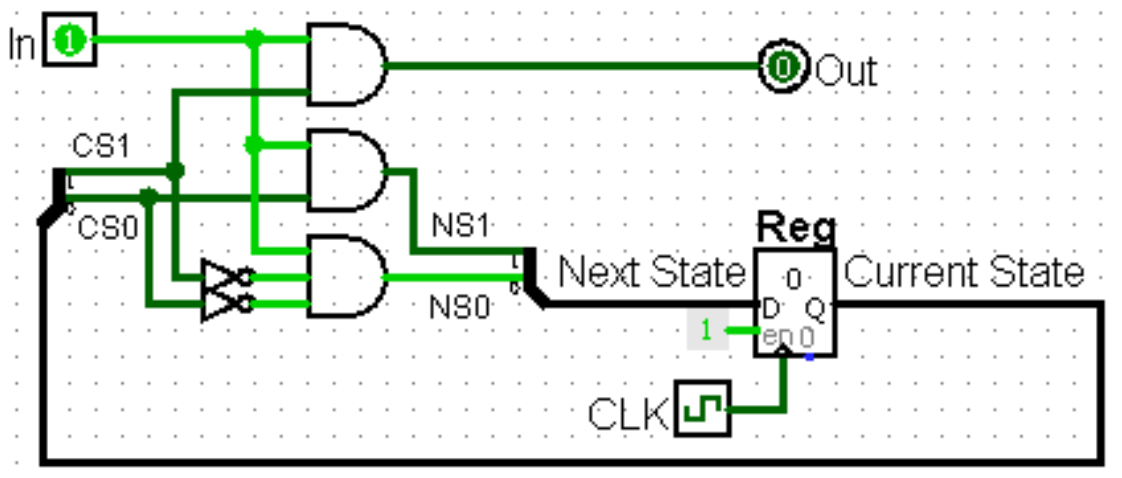
CL: NS1 = CS0In, NS0 = ¬CS1¬CS0In, Out = CS1In
然后便可以用组合逻辑电路实现
General Model for Synchronous Systems
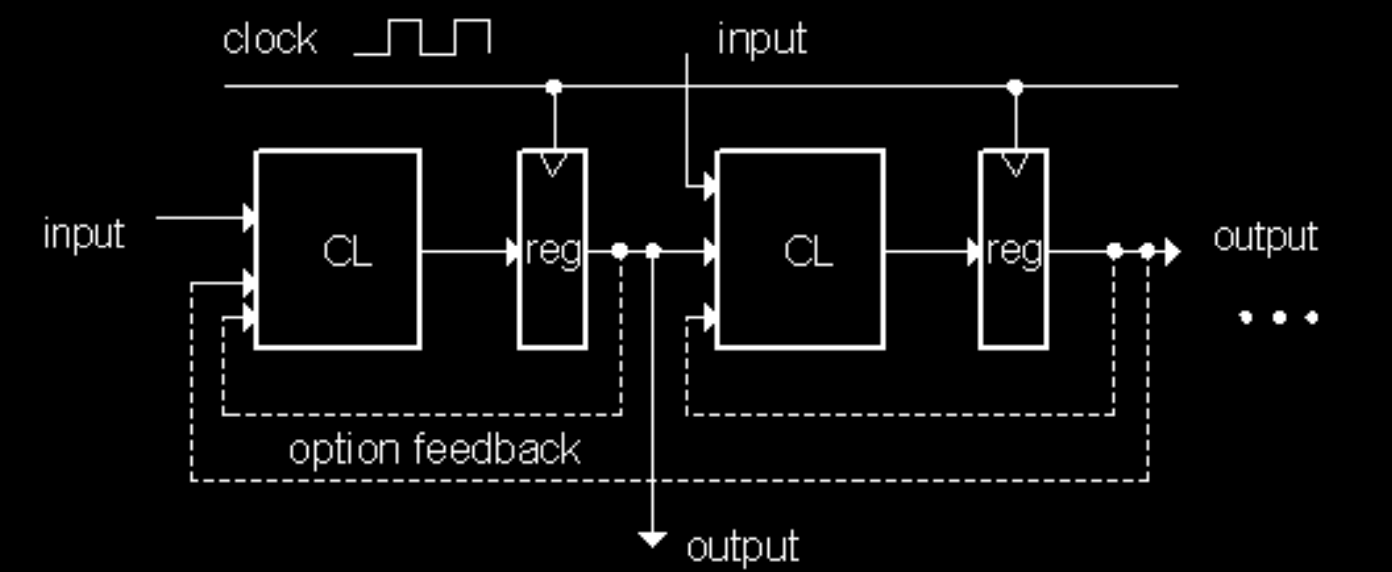
Functional Units
Arithmetic and Logic Unit
绝大多数处理器都有一个ALU单元,一个ALU就可以完成加减与或的运算
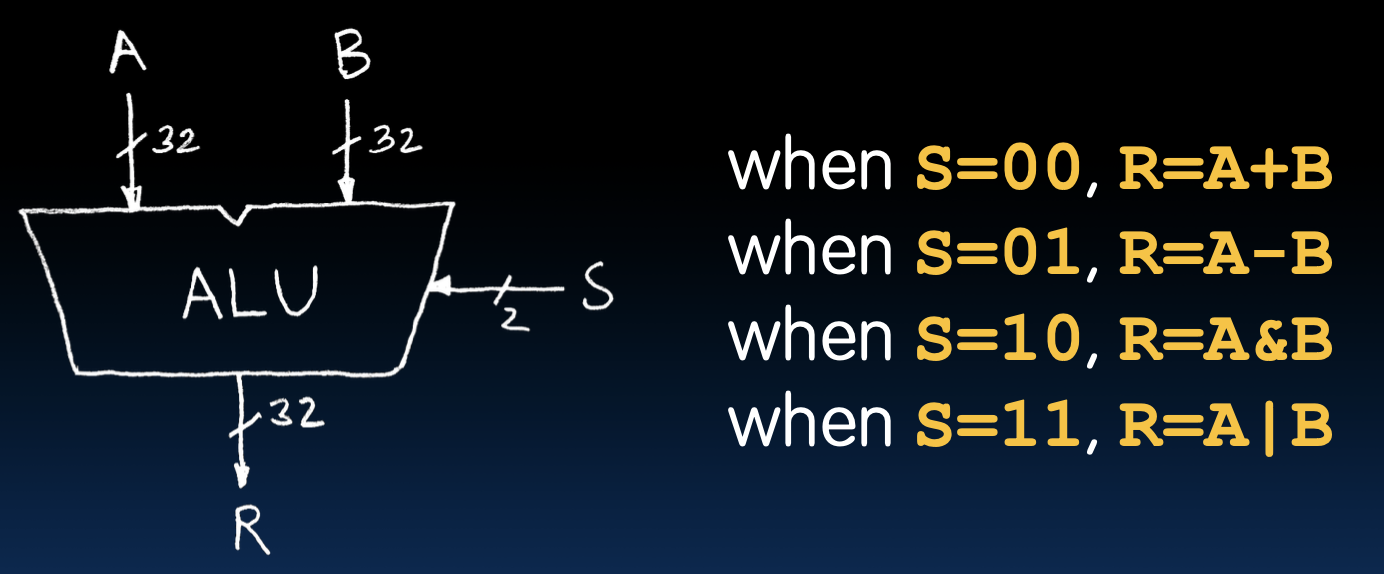
很好,如果我们要根据真值表来实现,那么你就得画
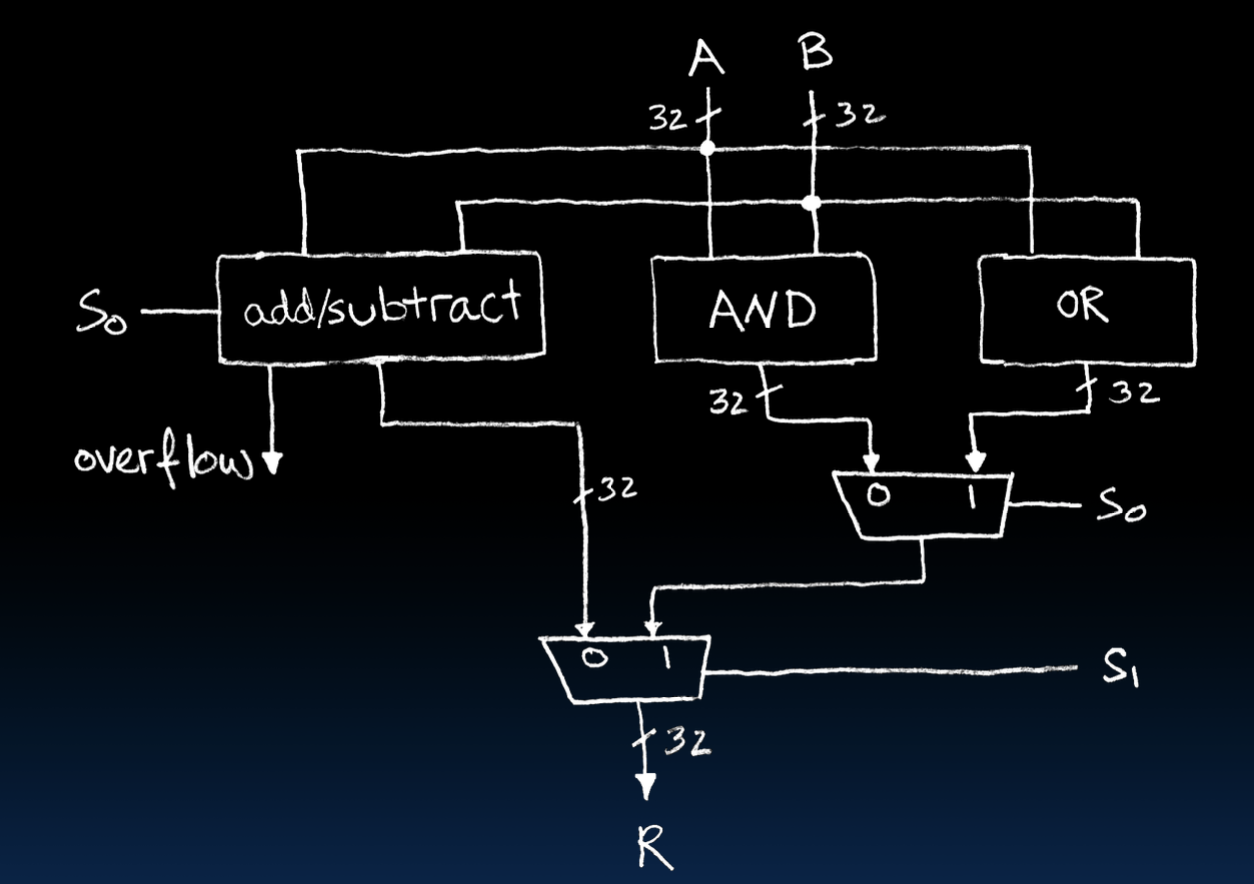
注意一点,实际上这三个值是同时被运算的,但是只允许有一个结果被输出
Adder/Subtractor
接下来,我们将逐步的来实现从一位加法器到N位加法器,包括讨论无符号数和有符号数的溢出情况。
首先我们来讨论1位加法器的最低有效位,单独讨论是因为最低有效位并没有来自上一位的进位(因为根本没有上一位)
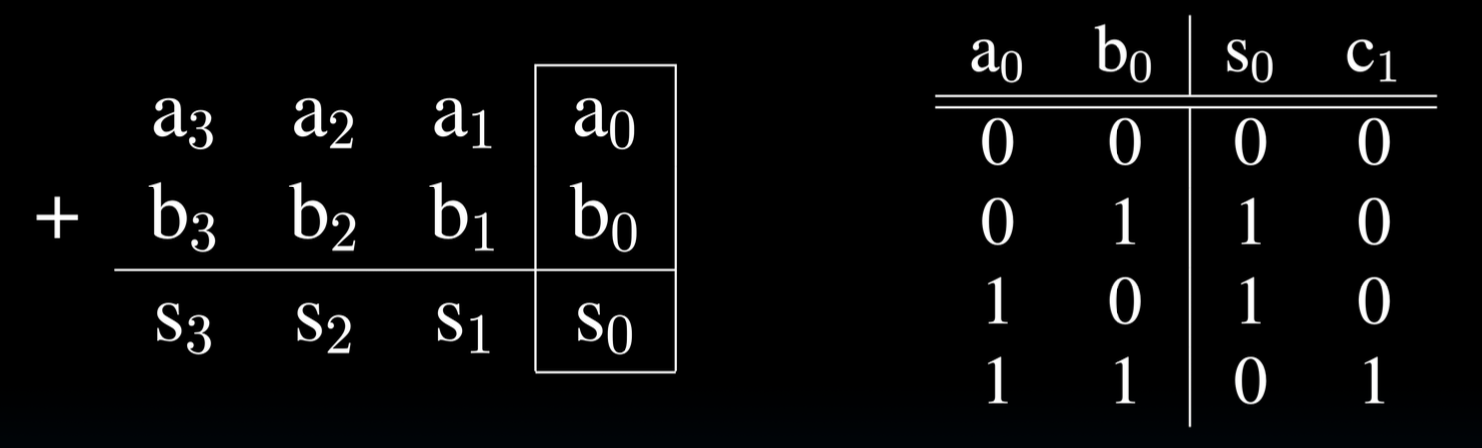
观察真值表可以得出,
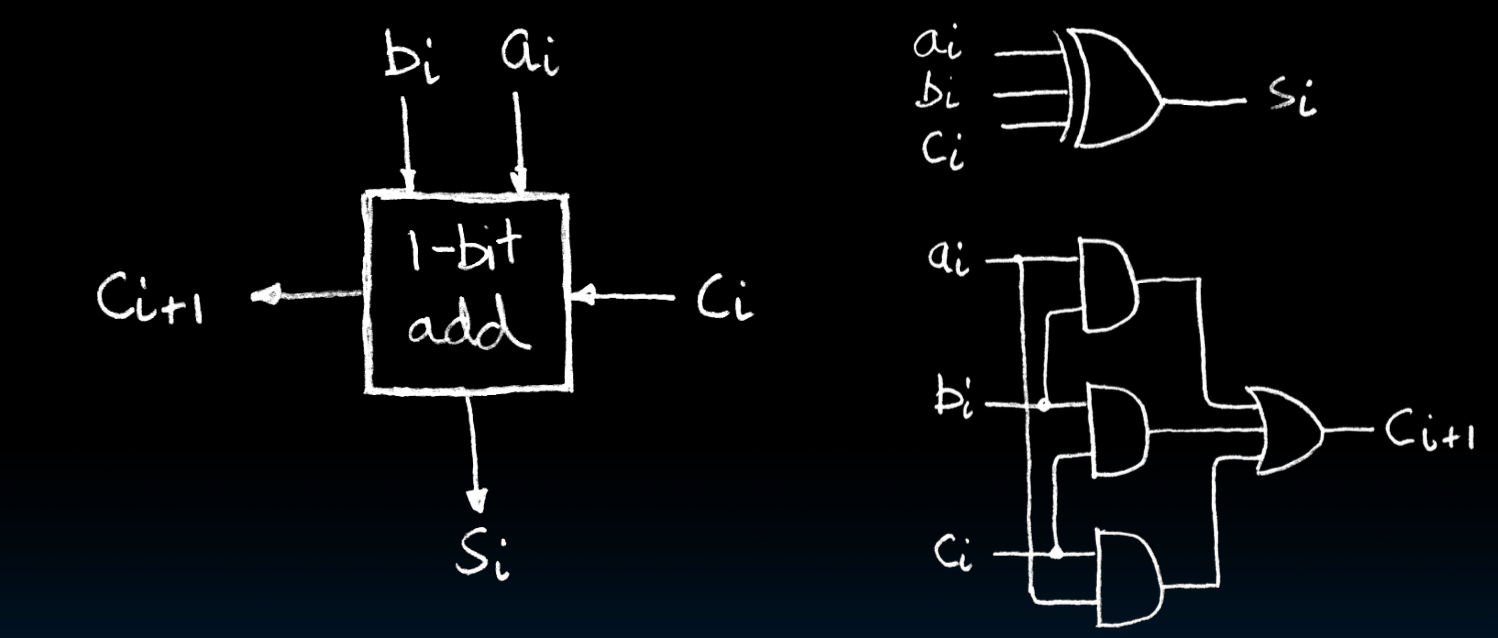
我们再来看一下除了最低有效位以外的1位加法器

观察一下S位,发现依然是异或,不过现在变成三个输入位的异或了,a,b还有一个由上一位产生的进位c。观察C位,则是一个多数电路(Majority circuit)
所以我们有
现在,我们要将N个1位加法器变成一个N位加法器
其实就是简单的串联到一起
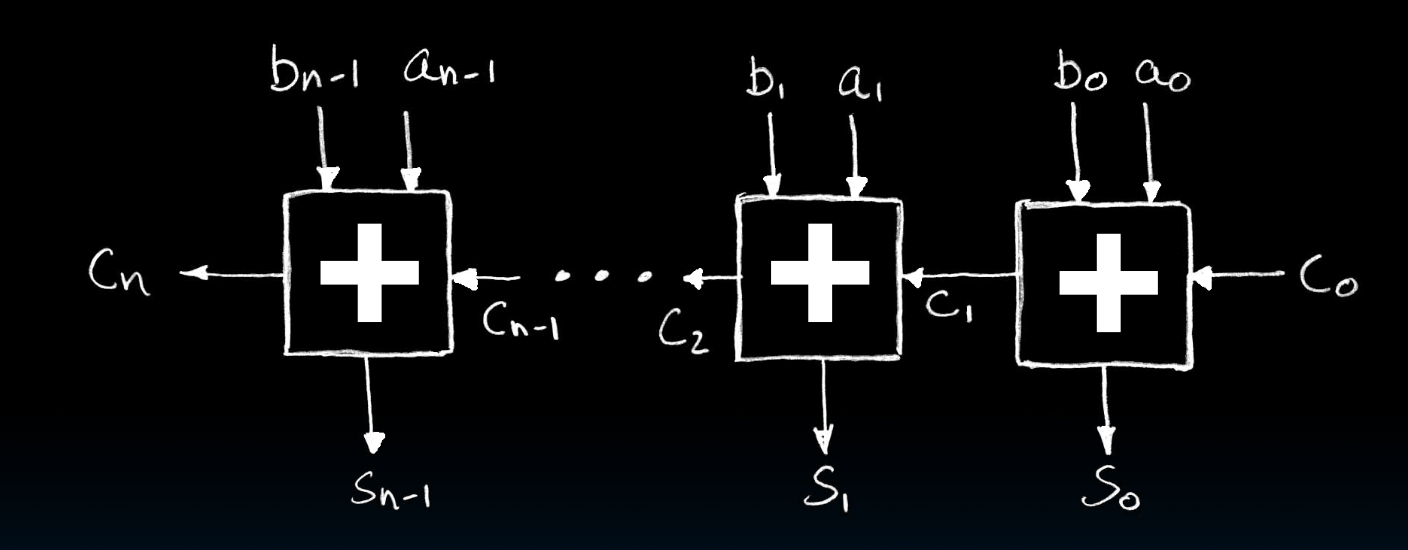
好了,现在的问题是,溢出该如何表示,换句话说,我们怎么知道有没有溢出呢。
- 无符号数
对于无符号数而言
overflow =
- 有符号数
对于有符号数来说
overflow =
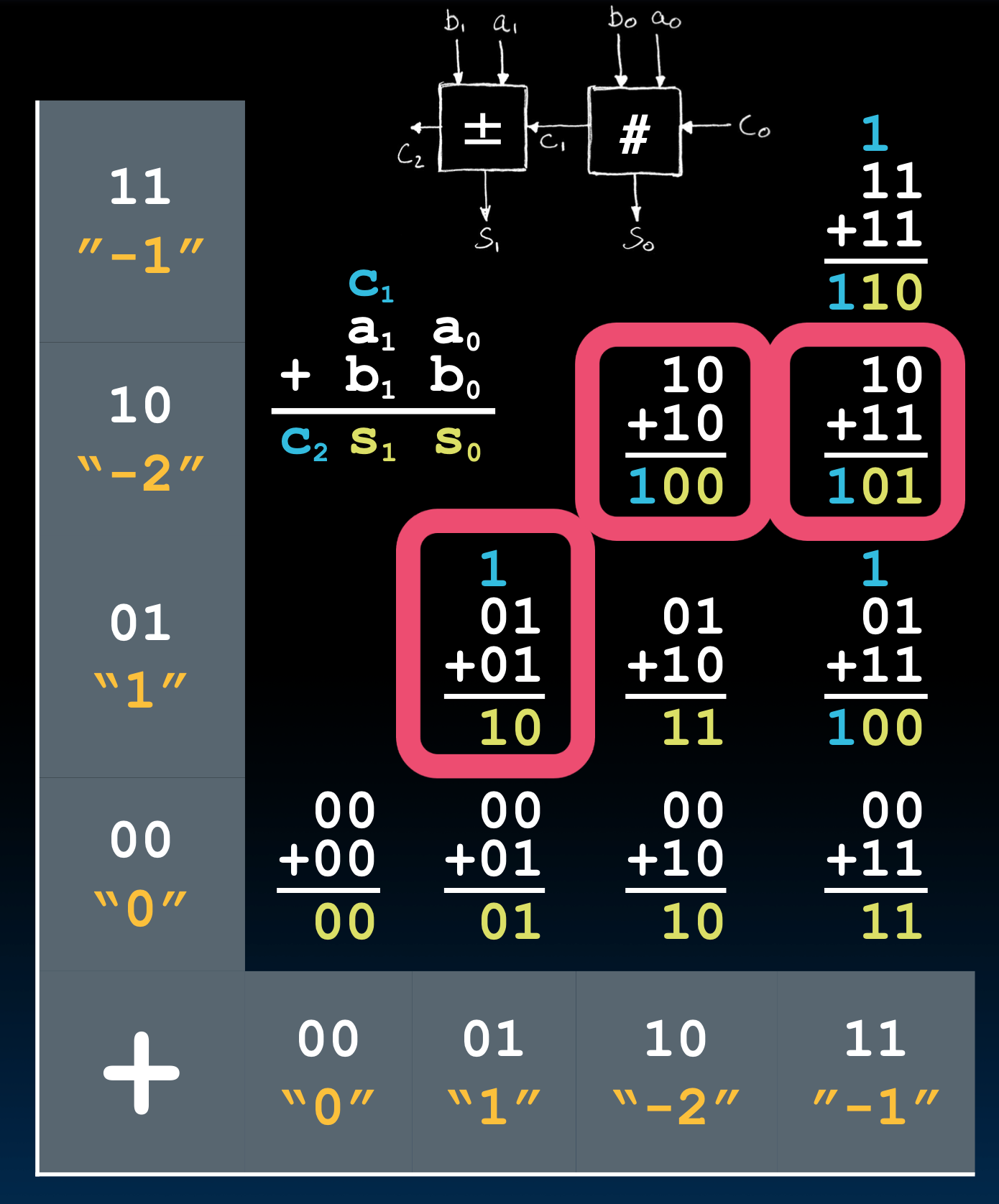
接下来我们看一种极其巧妙的在加法器的基础上实现减法的做法!非常优雅
首先XOR可以看作是条件翻转器,x为0的时候,输出就是y,但如果x是1,输出就是非y。
我们都知道,负数的补码是原码取反加一,那么我们就可以用XOR来实现取反,那么加一呢?
将取反的线接到第一个1位加法器的进位上!就可以优雅的实现减法器了!
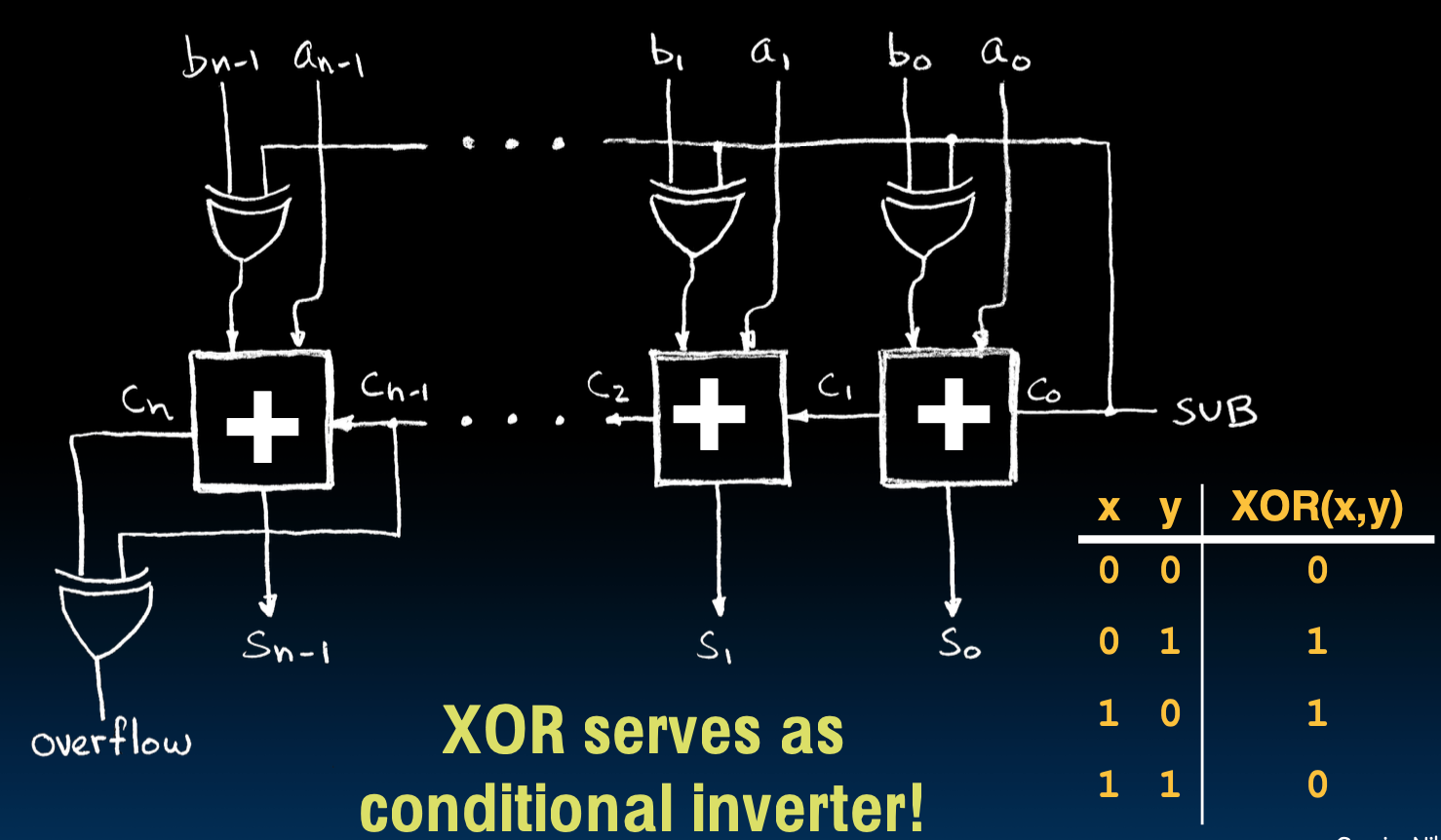
注意,上面的overflow是有符号的溢出,无符号溢出可以直接从Cn引出一条线来表示。
